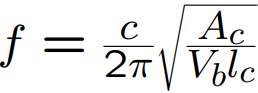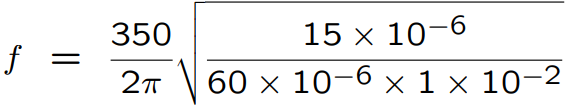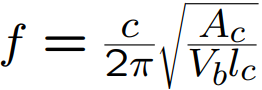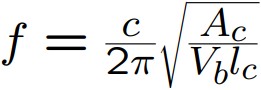A Digital Man - Hidden Truth Imagine Secret behind Invisible Voice
.
.
Understanding of the Term "MOUTH" related to this mission.
Click below to Listen ...
Note: Buttons are not in black means its loading...please wait
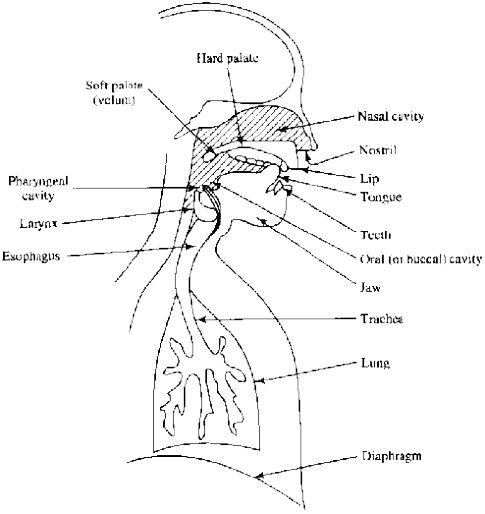
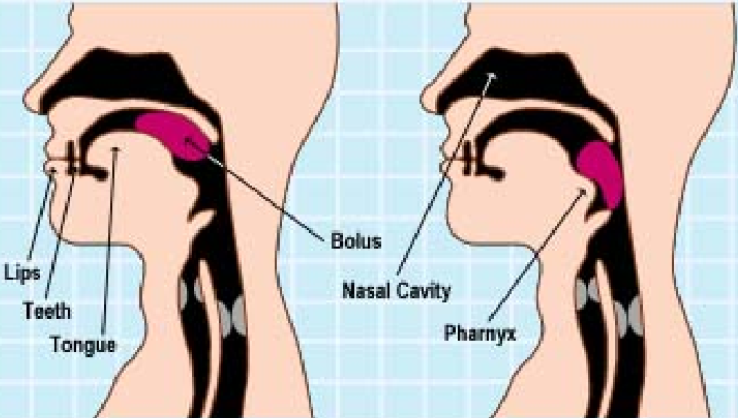
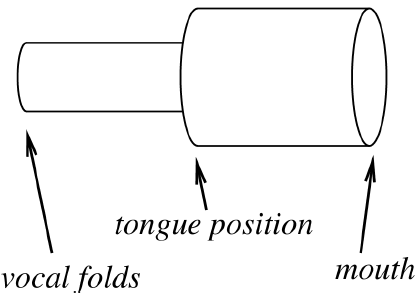
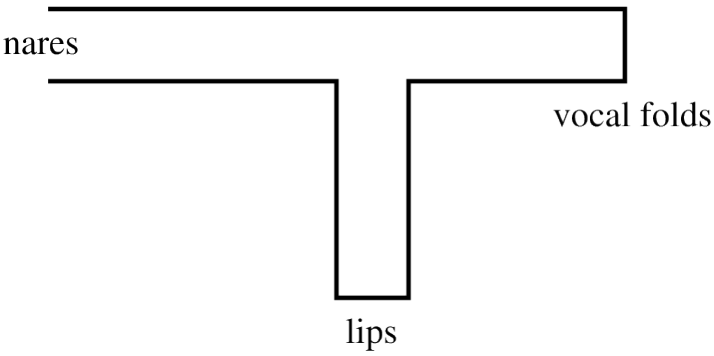
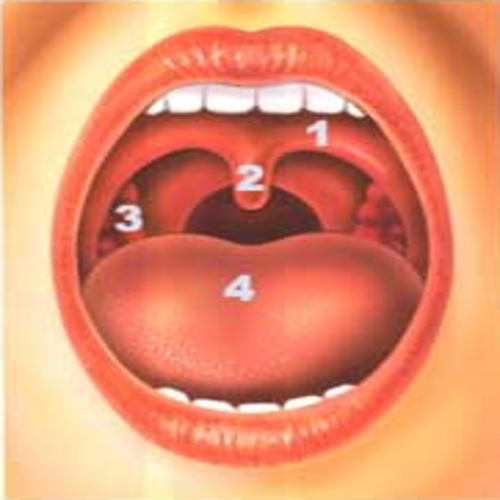
The Human Mouth.
The Human Mouth, plays a key role in voice production, and speech.
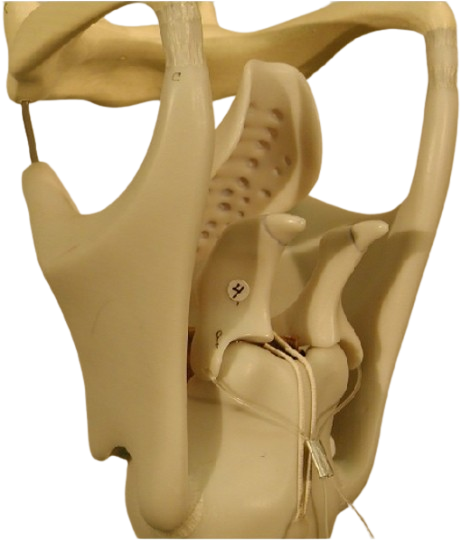
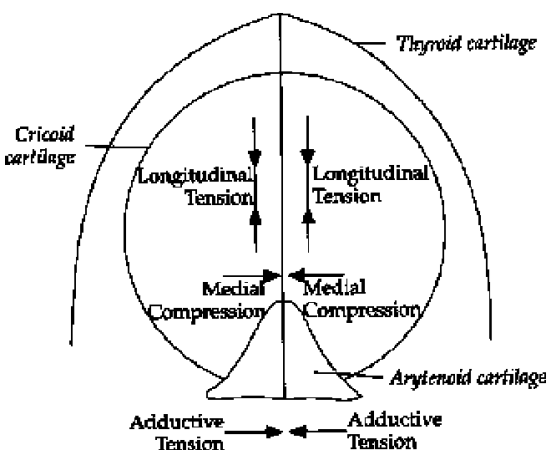
The Vocal cords:
When the air, from the lungs passes through, the vocal folds in the larynx, the folds vibrate, to produce sound.
The pitch of the sound, depends on the force of the air, and how tight the vocal cords are.
The Tongue and The lips:
These move, to shape the sounds, into speech.
The Human mouth other structures:
The hard, and soft palates, and nose, also help produce sounds.
Movements of the tongue, and lips help, to shape the sounds.
The Human mouth other structures involved, in the production of sounds, include the hard, and soft palates, and the nose.
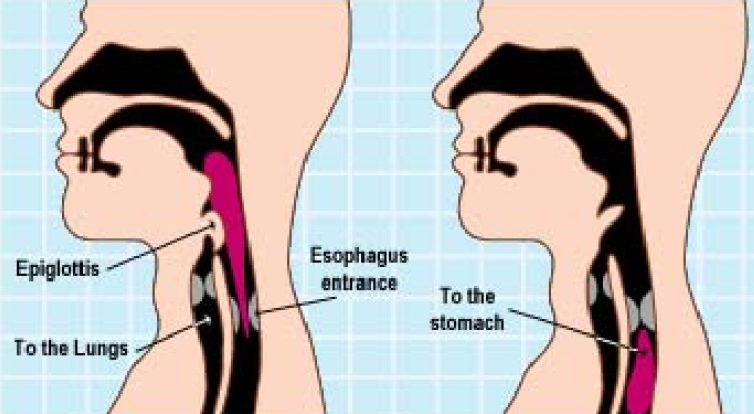
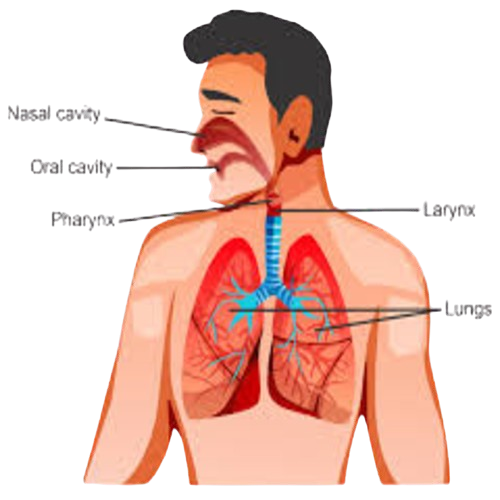
The Sound is produced, when the air, which passes through the vocal cords, causes them to vibrate, and create sound waves, in the pharynx, nose, and mouth of the Humans.
The pitch of sound is determined, by the amount of tension, on the vocal folds.
The voice continues to vibrate, as it travels up, through the Human Throat, and into the Human mouth, and the Human Nose, and into the Human mouth, or the Human Nose.
Humans can, then control the flow of air, using your lips, tongue, teeth, and the roof of your mouth, to make different sounds.
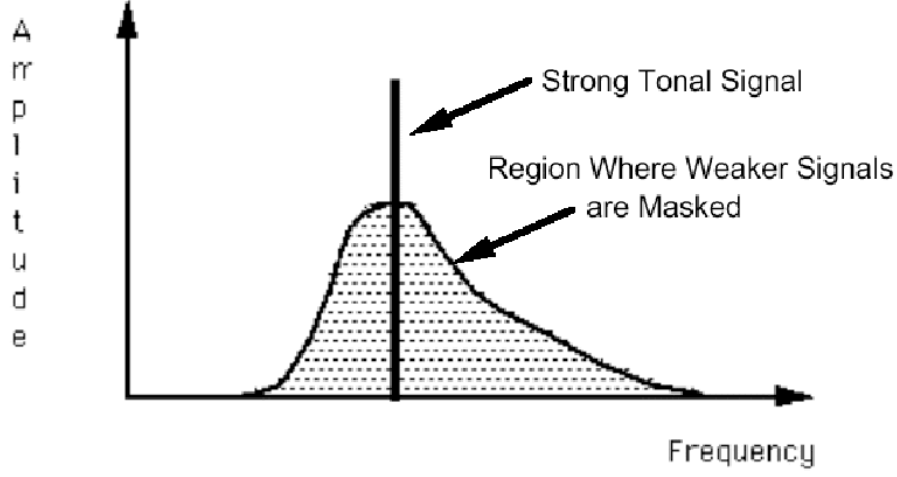
The Sound is produced, when aerodynamic phenomena, cause vocal folds to vibrate, rapidly in a sequence of vibratory cycles, with a speed of about:
For the Men, 110 cycles per second or Hz = lower pitch.
For the Women, 180 to 220 cycles per second = medium pitch.
The human mouth is involved in the production of sound in several ways.
Vocalization:
When air, from the lungs passes through, the vocal cords in the larynx, the cords vibrate, and produce sound.
The type of sound, depends on the force of the air, and how tight the vocal cords are.
Shaping sounds:
The tongue, lips, hard palate, soft palate, and nose, work together to shape the sounds, into speech.
Resonance chambers:
The pharynx, larynx, mouth, nasal cavity, and paranasal sinuses modify sound waves.
Oral cavity:
The position of the human mouth, also known as, the oral cavity, determines the sound that is produced.
What sound is produced by the human mouth?.
When the air, from the lungs blows, through the vocal folds, at a high speed, the vocal folds vibrate.
The vibrations lead to sounds, we call voice.
These sounds are shaped, to form speech.
Coordinated movements mainly, by the tongue, and lips, and in the nasal passages, that produce recognizable sounds, called speech.
The human mouth is involved, in several aspects of noise, including.
Human Mouth sounds:
Sounds made by the mouth are produced, when air from the lungs passes, through the vocal tract's muscles, causing vibrations, that are audible.
The pharynx, larynx, mouth, nasal cavity, and paranasal sinuses, modify the sound waves, which can be prolonged, amplified, or changed.
The muscles, in the pharynx wall, as well as, the muscles in the face, tongue, and lips, can also modify the sound, to produce speech.
Human Noisy breathing:
It can be caused, by a partial blockage, or narrowing in the airways, which can occur in the mouth, nose, throat, larynx, trachea, or lungs.
Some types of noisy breathing, include.
Stertor:
A low-pitched noise, that sounds like nasal congestion, or snoring.
Stridor:
A higher-pitched noise, that occurs, when there is an obstruction in, or just below the voice box.
Wheezing:
A high-pitched noise, that occurs during expiration.
Hearing through the human mouth:
It is possible to hear, through the human mouth, when the eardrum is defective.
Some ways to hear, through the human mouth, includes.
Pressing a vibrating metal disk, against the upper teeth.
Listening to very soft sounds, through the mouth.
Blowing directly onto metal springs, with a mouth instrument.
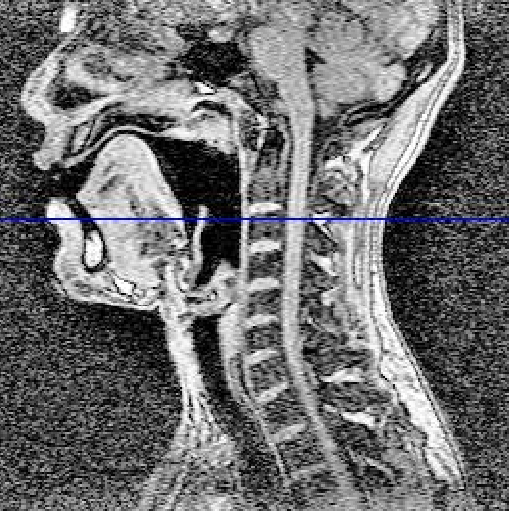
The Anatomy of speech production.
- the sources of sounds.
- Modifying that sound to make speech.
Respiratory system: lungs, vocal tract, (oral cavity, nasal cavity).
Speech organs: the sound source for voiced sounds – vocal folds.
Airflow.
Lungs: ingressive vs egressive sounds.
Why is airflow needed?.
As an energy source, to drive the vocal folds, or for unvoiced sounds.
The lungs.
Primary function: respiration – transfer oxygen into the blood and remove CO2 from the blood.
Secondary function: energy source for speech.
Air flow.
Air pressure.
Typical lung capacity 2 to 5 litres.
The vocal folds: airflow.
How do humans get vibration from airflow?
“Blowing a raspberry”.
Is there airflow?.
Can you do it without airflow?.
What process is involved?.
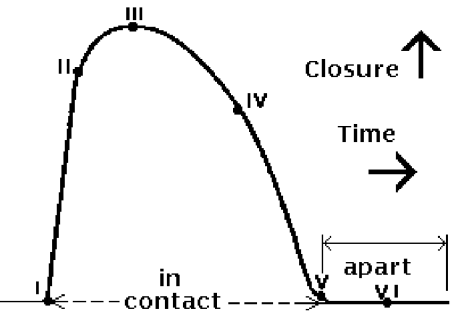
The vocal folds: vibration.
Temporarily stop the airflow coming up from the lungs, pressure builds up, eventually, folds part and release pressure: a pulse of air travels up into the vocal tract, fold close again due to muscular forces, cycle repeats.
The vocal folds: in action.
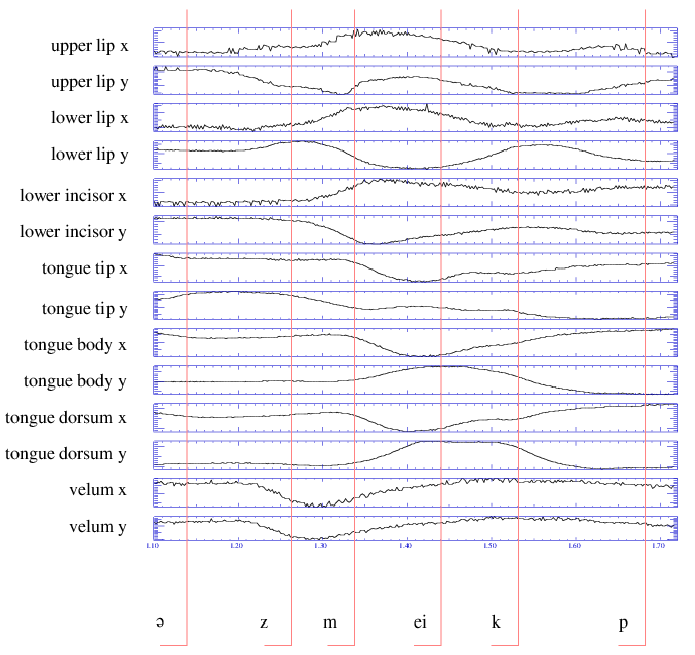
In below Images, it shows.
The vocal folds: control.
How can we control?.
– whether the folds vibrate at all.
– the frequency of vibration.
Tension of the vocal folds.
– try blowing low and high frequency “raspberries”.
– what are you doing to control frequency?.
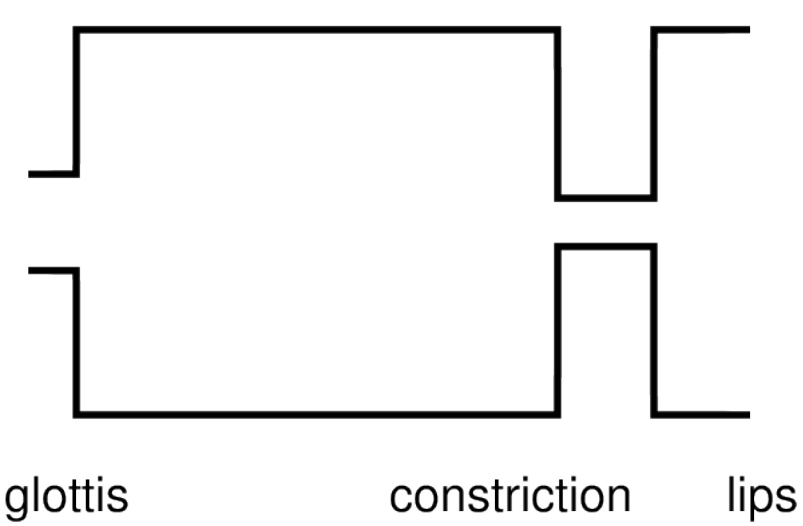
Unvoiced sound sources.
Fricative sounds: Turbulence.
Plosive sounds: Sudden release of intra-oral air pressure.
Not considerable sounds, with no air flow. (Example: clicks).
Turbulence.
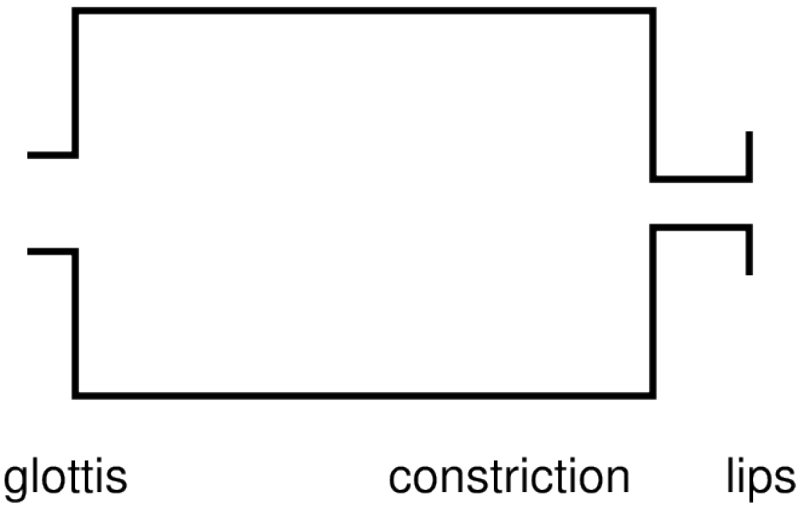
Steady smooth airflow.
Example: breathe out with relaxed vocal tract and relaxed vocal folds.
No sound.
Disturbed airflow.
Example: something placed in the airstream.
Compare to: leaning out of window of speeding car.
In speech.
– airflow generated by lungs.
– what creates the turbulence?.
Constrictions.
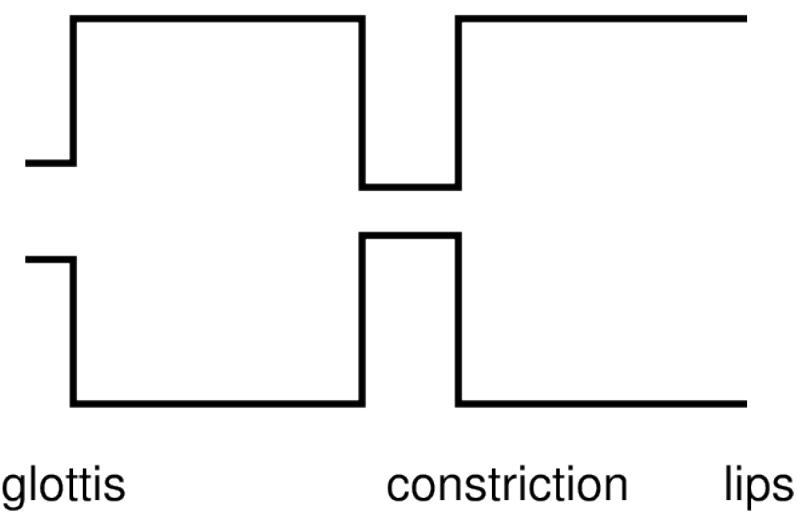
Example 1: tongue + upper incisors [th].
Example 2: upper incisors and lower lip [f].
Plosives.
Temporary complete interruption of the airplow.
– no airflow out of the mouth or nose.
– air continues to flow from the lungs.
– pressure builds up.
– eventually pressure overcomes the “blockage” and air is suddenly released.
Example: Like a champagne cork popping.
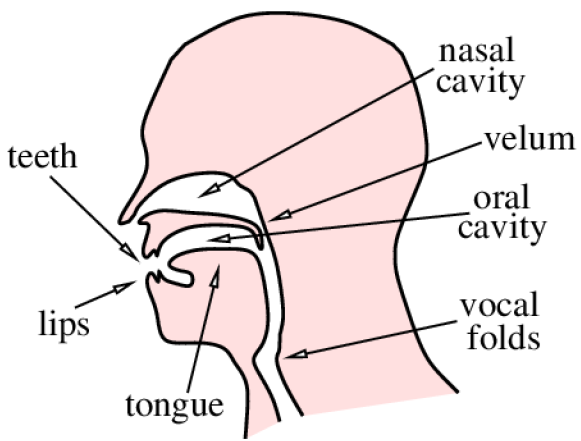
Anatomy of the articulators.
Velum.
Tongue.
Jaw.
Lips.
The vocal tract.
In below Images, it shows.
Speech production - general anatomy.
In below Images, it shows.
Swallowing.
In below Images, it shows.
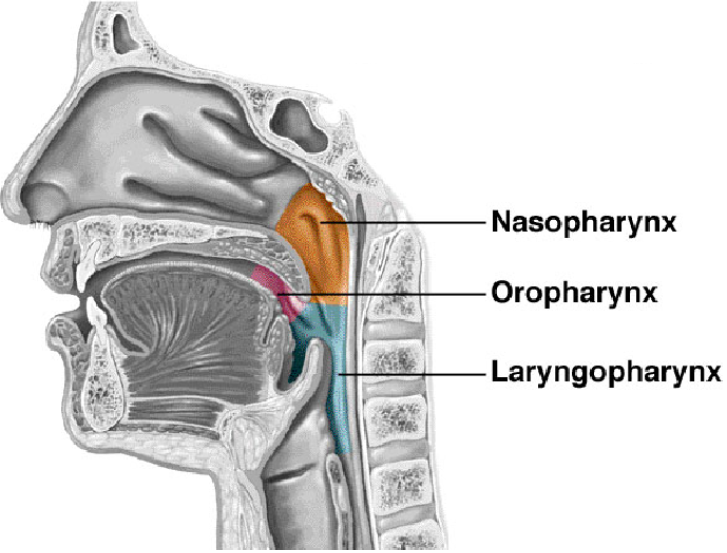
The Regions of Pharynx.
In below Images, it shows.
The oral and nasal cavities.
In below Images, it shows.
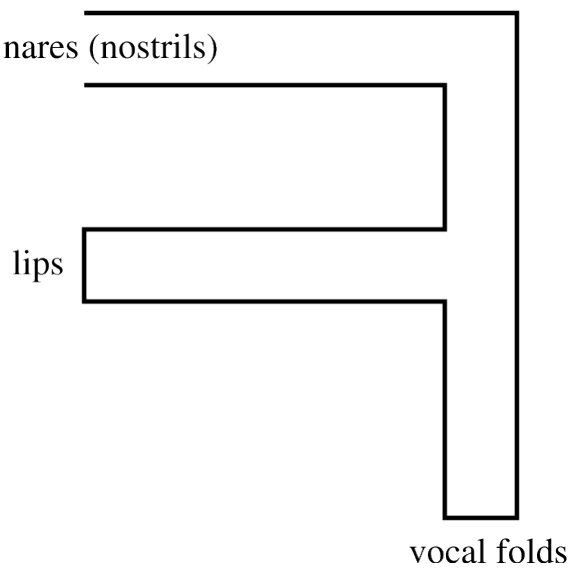
The articulators: velum.
Need to connect/disconnect nasal cavity from oral cavity.
Velum resting position is down.
– nasal cavity connected.
– can breathe in/out through mouth or nose.
For most speech.
– velum moves up to close off nasal cavity.
For nasal sounds.
– velum remains down.
The articulators: tongue.
• most important articulator.
• capable of complex movements.
• can change shape.
– can raise different portions of the tongue.
– can alter cross-section of tongue.
– can raise different portions of the tongue.
– can make or approximate contact with the palate.
– contact only at edges: grooving, Example: /s/, /z/.
– contact only in centre, open at sides: laterals, Example: /l/.
– complete closure: oral stops, Example: /t/, /d/.
• controls shape of oral cavity.
– up/down, front/back movements.
– affects shape and size of cavities.
– cavities resonate = formant frequencies.
Exactly how these resonances can be modelled.
The articulators: jaw.
• often forgotten, but an important articulator!.
• controls size of oral cavity.
• controls position of lower incisors.
– Example: constriction required to produce /f/, /v/.
For some vowels the tongue effectively divides the vocal tract into two cavities, each with it’s own resonance.
In that case, lip rounding enlarges the front cavity and lowers it’s resonant frequency.
One step closer to a model.
.
• how does all this anatomy help?.
– vocal tract / oral and nasal cavities.
– can model them as tubes.
– tubes resonate.
• The resonant frequency of a tube, and of connected tubes.
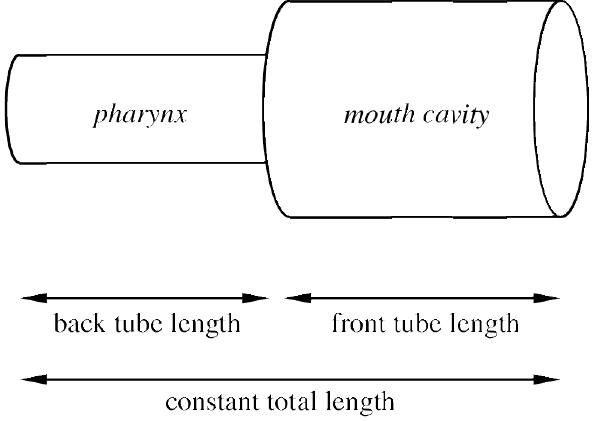
Vocal tract as two tubes.
• tongue creates a constriction.
– part of tongue is raised towards palate.
• position and size of constriction can move front <---> back, high <---> low.
• vocal tract can be modelled as two connected tubes.
Two tube model.
In below Images, it shows.
Tract has back cavity and front cavity.
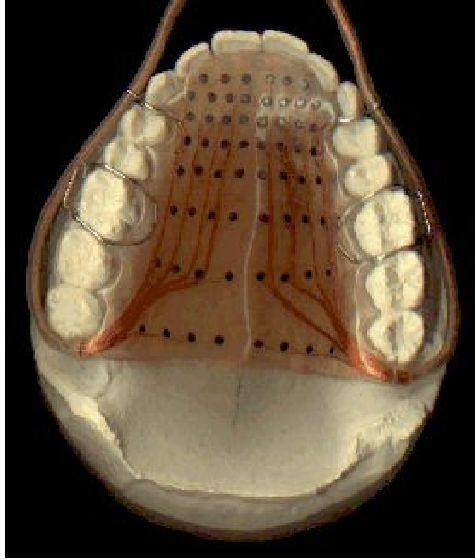
Measuring articulation.
How can we really know exactly what the articulators are doing?.
Precisely locates position, size and shape of tongue-palate contact.
Sounds such as.
– /t, d, k, g, s, z, S, Z, tS, dZ/.
– the palatal approximant /j/.
– nasals /n, N/.
– lateral /l/.
– relatively close vowels such as /i, I, e/.
– diphthongs with a close vowel component such as /eI, AI, oI/.
EPG palate:A grid of 62 silver contacts embedded in a hard plastic palate, Must be custom-made for each person.
In below Images, it shows.
Laryngograph.
Measures vocal fold activity essentially, measures glottal width can plot frequency of vocal fold vibration, that is F0.
Also known as an electroglottograph.
In below Images, it shows.
Measuring articulation: the tongue and velum.
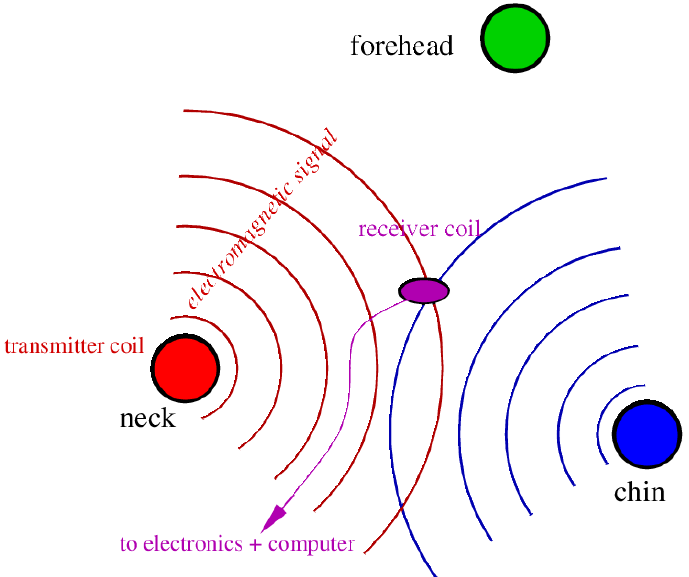
Electromagnetic articulograph (E M A).
What does it measure?.
How does it work?.
Electromagnetic articulograph (E M A).
In below Images, it shows.
E M A.
Helmet with three transmitter coils.
– transmit high frequency signals (think of them as radio waves).
Tiny receiver coils attached to points of interest.
– several on tongue.
– lips.
– lower incisors (jaw).
– lips.
– possibly also velum.
Distance between receiver and transmitter coils can be calculated automatically (and in real time – typically 500 times per second).
– so, can plot 2-dimensional position of receiver coils, that is, low–high and front–back.
– accurate to within around 1 mm, (Millimeter).
Receiver coils must be mid-saggital, that is, in centre.
– so cannot see tongue grooving, for example.
In below Images, it shows.
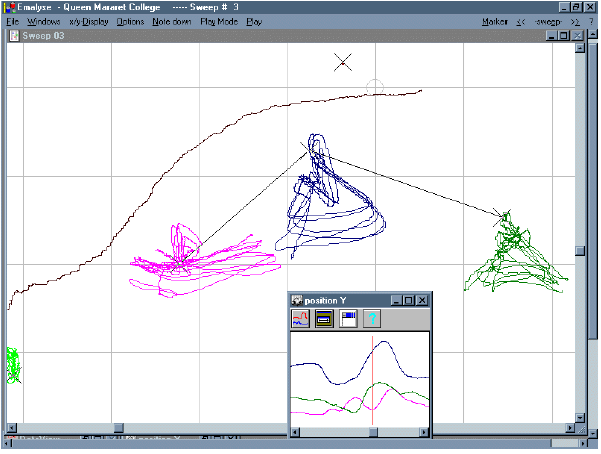
EMA data.
In below Images, it shows.
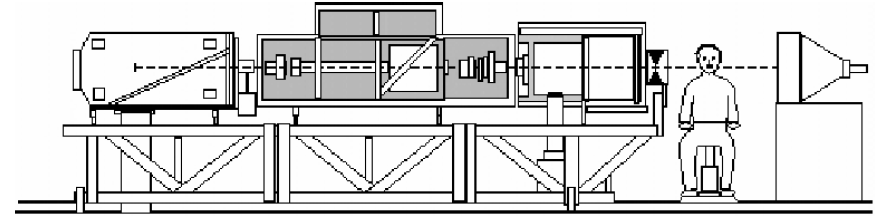
X-ray cinematography.
Full frame movie.
– therefore relatively large X-ray dosage!.
Shows all articulators: jaw, velum, tongue, lips.
Only shows “cross-section” of head, so impossible to see tongue grooving, for example.
X-ray microbeam.
Gold pellets attached to points of interest.
Narrow beam of X-rays tracks the pellets.
– relatively low doses of X-ray.
– but subjects can still only record limited amounts of data.
Machine quite noisy.
– recorded speech signal not very high quality.
– may even affect way speaker produces speech.
X-ray microbeam: Large, very expensive equipment.
In below Images, it shows.
Airflow masks.
Example: Rothenburg mask.
In below Images, it shows.
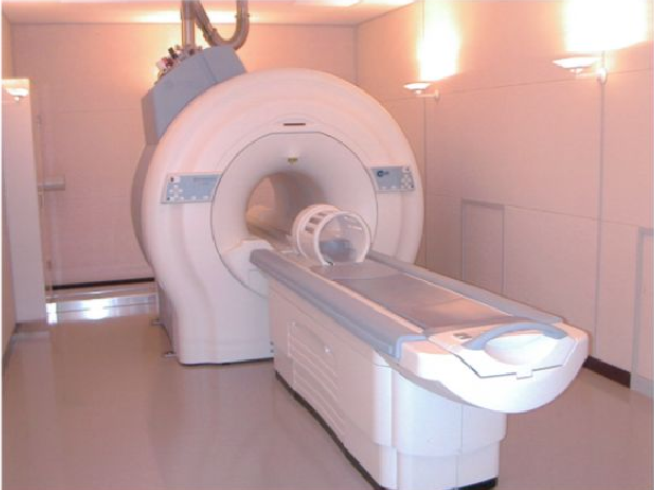
Magnetic-resonance scanning.
Example: fMRI.
Full 3-D picture of body organs and cavities (Example: vocal tract).
Fairly high resolution.
But a complete scan too slow for speech.
– can take several seconds.
– so cannot (with current technology) get moving images.
– user must “freeze” articulator positions during scan.
Technology always improving towards 3-D full motion images of vocal tract.
fMRI.
In below Images, it shows.
Two-tube models of vowels.
First, recap one-tube model, then, two-tube models.
– still very simple model.
– each tube has it’s own resonance(s).
Formant frequencies of some more vowels.
One-tube model.
In below Images, it shows.
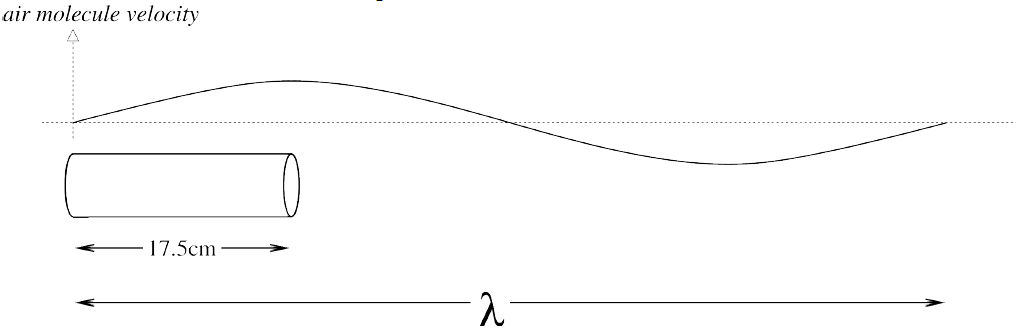
λ = 4 X 17.5 cm (centimeter) = 70 cm (Centimeter) = 0.7 m (Meter).
f = c/λ = 350ms-1 / 0.7 m (Meter) = 500 Hz.
Multiple resonances in the same tube.
In below Images, it shows.
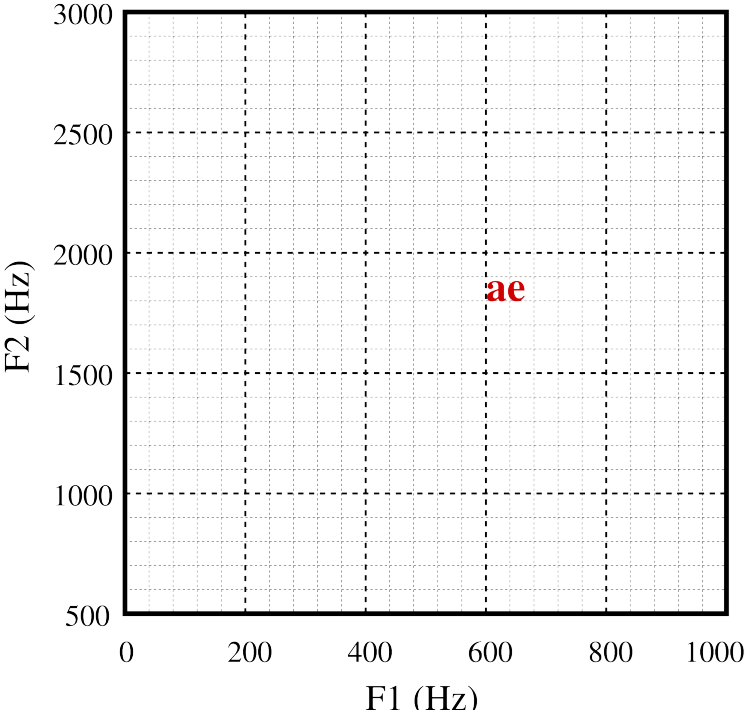
This model predicts that the first three formants of [ə] , schwa, vowel, (upside-down e), are 500Hz, 1500Hz and 2500Hz.
How accurate is the model?.
If a tube is much longer than it is wide, that is, if length > 4 X width.
It is resonances depend only on it is length.
Is this true for the vocal tract?.
• length around 17.5 cm (centimeter).
• width varies from few mm (millimeter) to 3.5 cm (centimeter).
so yes, it is true.
Two tubes.
• why two tubes?.
– vocal tract shape not uniform for vowels other than [ə] , schwa, vowel, (upside-down e).
• still a very simple treatment.
– tubes act independently.
that is, treat each one like the simple tube for [ə] , schwa, vowel, (upside-down e).
• what are the lengths of the tubes?.
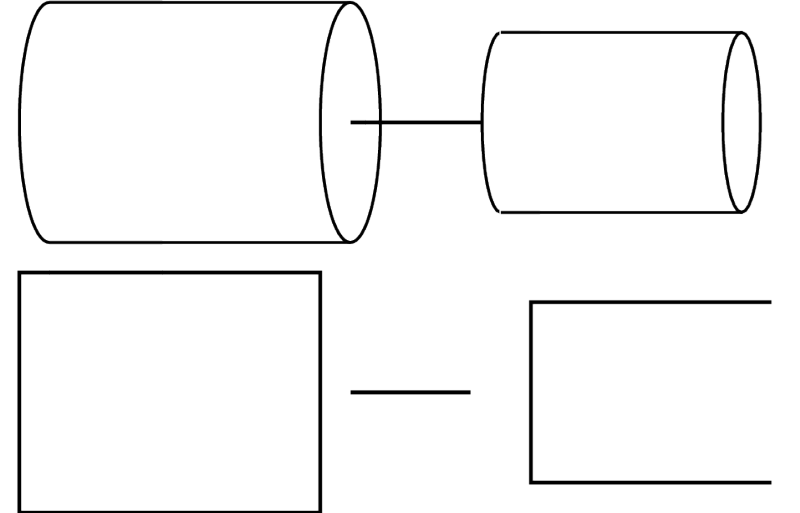
A two-tube model.
• tongue position.
– low.
– back.
• lips.
– unrounded.
• velum.
– raised.
That is, it is a low, back, unrounded vowel.
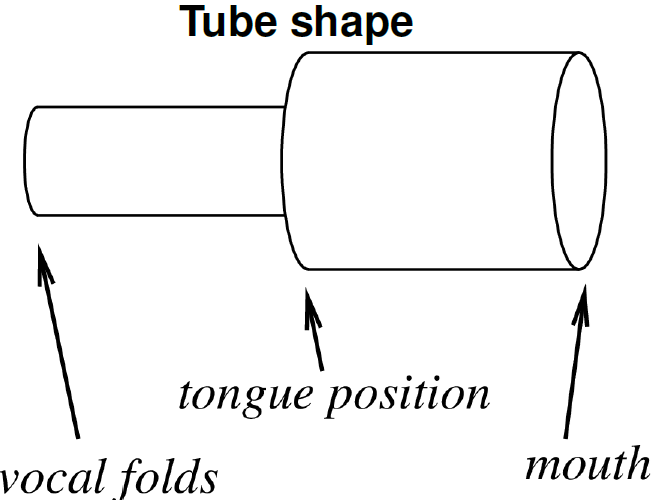
Tube shape.
In below Images, it shows.
Tube dimensions.
In below Images, it shows.
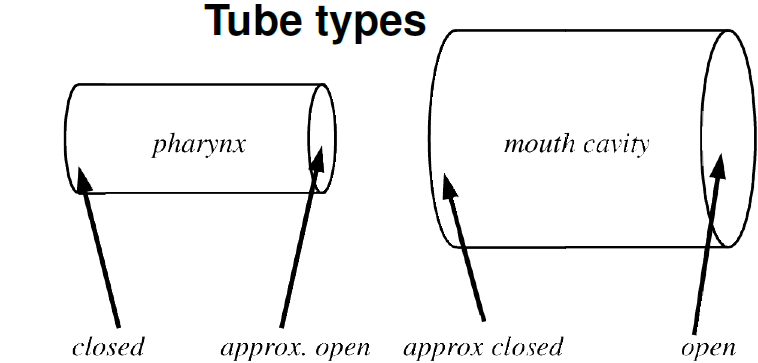
Tube types.
In below Images, it shows.
That is, both tubes are (approximately) closed at one end and open at the other.
Resonances of the two tubes.
Both tubes are still much longer than they are wide, so the resonance dependes only on the length.
Both tubes have same length, which is half vocal tract length, so resonances of each tube will be twice those for the [ə] , schwa, vowel, (upside-down e) model.
that is, 1000 Hz, 3000 Hz, 5000 Hz, ....
which means F1 = 1000 Hz.
A small complication.
in reality....
Tubes are not completely independent.
– the pahrynx tube is not exactly open at one end - it connects to the mouth tube.
– and the mouth tube is not exactly closed at one end - it connects to the pharynx tube.
The effect of this coupling is that.
– the pharynx tube resonant frequencies drop slightly.
– the mouth tube resonant frequencies rise slightly.
The prediction.
So, For the low, back, unrounded vowel [a].
F1 is produced by the back tube and is about 900 Hz.
F2 is produced by the front tube and is about 1100 Hz.
How can F1 and F2 vary?.
The tube lengths must change, because the tongue moves position, can be predict possible values for F1 and F2 ?.
Varying length tubes.
In below Images, it shows.
As back tube gets longer, front tube gets shorter, and vice versa.
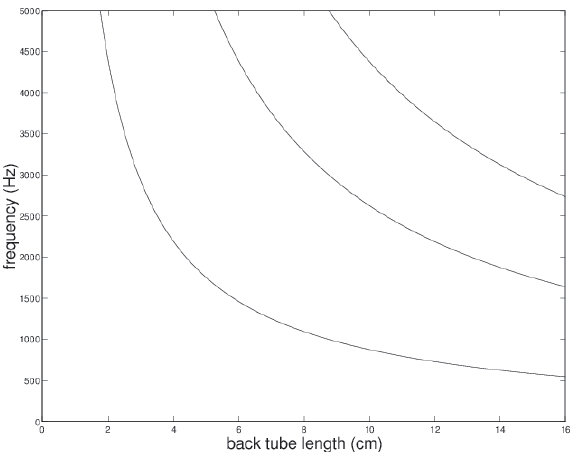
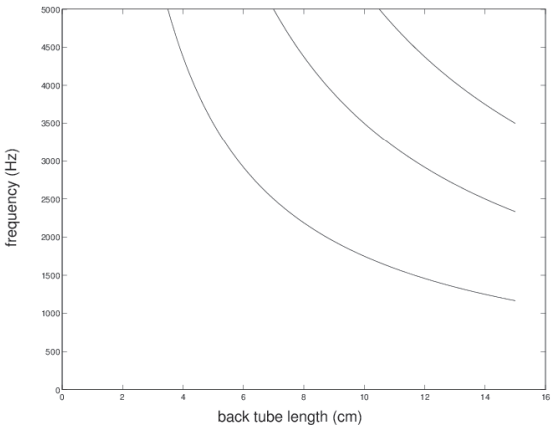
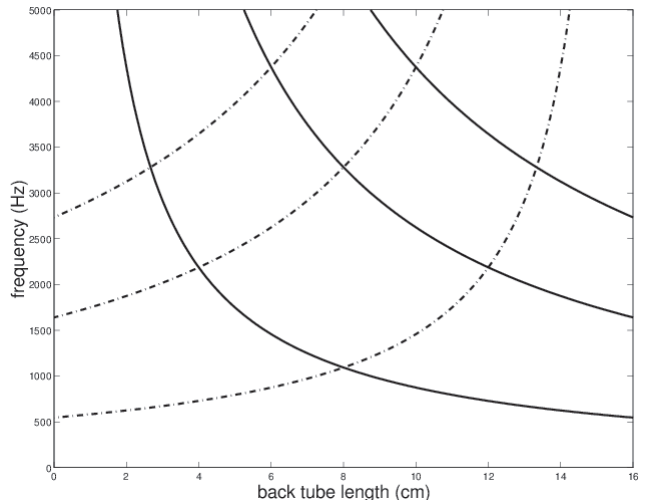
Back tube resonances.
Depends on back tube length.
– for length of 8.75cm we already predicted 1000Hz, 3000Hz, 5000Hz,...
Remember the formula c = f λ ?
From this we can write a formula for the resonances of a tube closed at one end, because the wavelengths that fit in such a tube are.
λ1 = 4 L,
λ2 = 4 L / 3,
λ3 = 4 L / 5,
in other words:
λn = 4 L / (2 n - 1),
where n = 1, 2, 3, ...
so:
fn = c / λn = (2 n - 1) c / 4L.
Relationship between f and L.
fn = c / λn = (2 n - 1) c / 4L.
An inverse relationship.
– as tube length L goes up.
– resonant frequencies fn all go down.
Let’s plot fn against L.
Plot of fn against L.
In below Images, it shows.
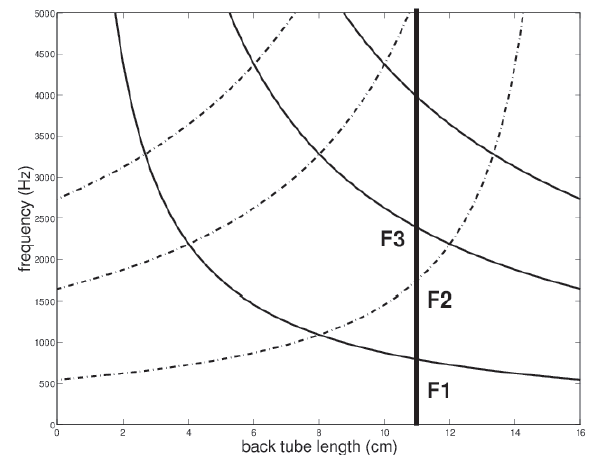
these are just the back cavity resonances: counting up from the bottom:
f1, f2, and f3.
These are NOT the formants ... yet.
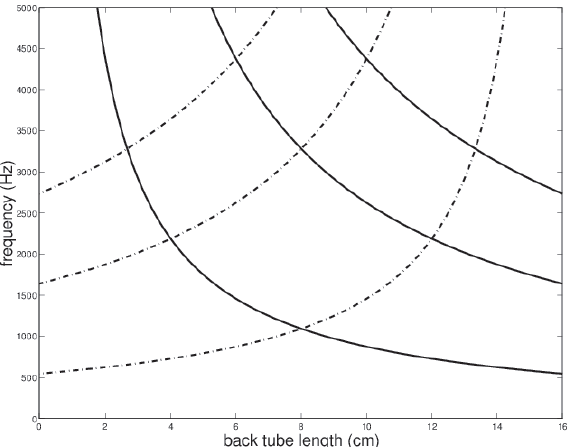
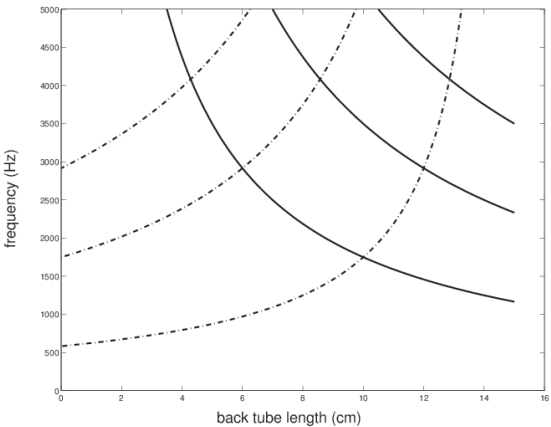
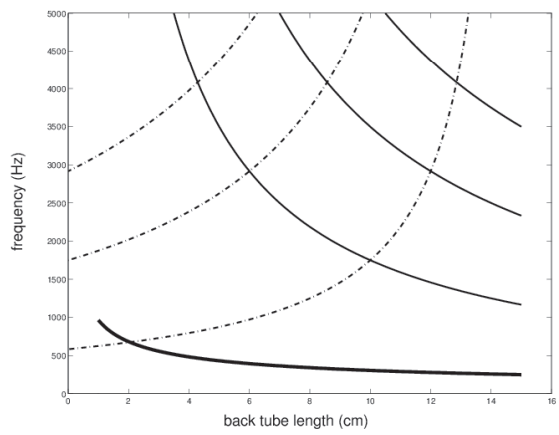
Plot of back and front tube resonances.
In below Images, it shows.
dotted lines are front cavity resonances.
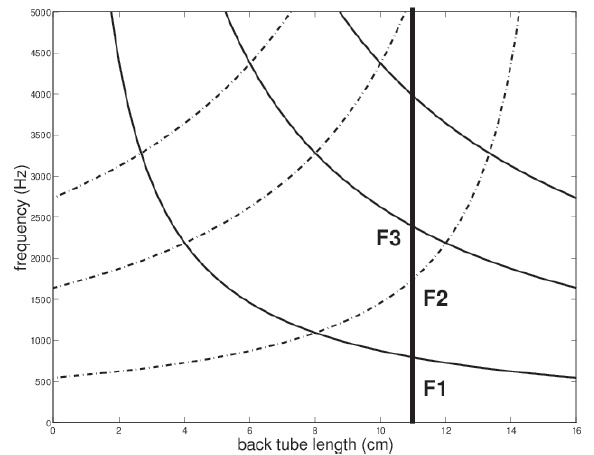
Working out the formants from this plot.
In below Images, it shows.
Pick a particular back tube length:
formants are counted up in order from lowest frequency to highest.
Does this tell us the range of possible formant values?.
It appears on the plot that F1 cannot go below 500 Hz, but we observe that in real speech, F1 can go lower.
Example: [i] as in “see” can have F1 as low as 250 Hz.
How is this possible?
Perhaps this model does not apply to [i] ?
Another type of tube model.
Two tube model can predict formant frequencies, Example: for [A].
– but appears to predict minimum F1 of 500Hz.
Some vowels such as [i] (as in “see” or “heed”) have lower F1, maybe as low as 250 Hz.
We need a better model (at least, for those vowels).
Recap - two tube model.
In below Images, it shows.
When is this model wrong?.
When the vocal tract is not like two tubes, each open at one end but when is that?
When one of the tubes is better approximated as being closed at both ends, or one of the tubes is better approximated as being open at both ends, or the two tubes have another mode of resonating.
Another tube configuration.
A narrow constriction near the front of the mouth.
– back tube is approximately closed at both ends.
– front tube is open at both ends.
– front tube is short and narrow.
Same as a wine bottle.
– bottle body is back cavity.
– bottle neck is front cavity.
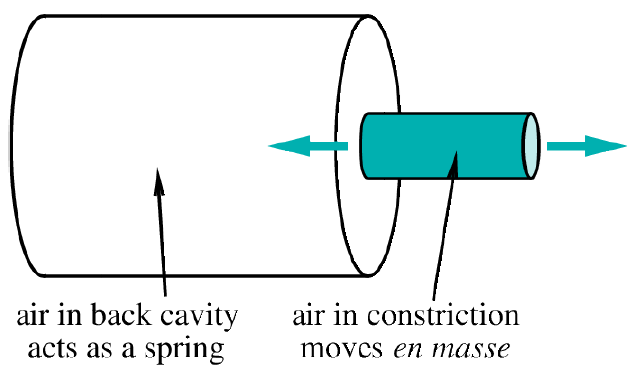
This type of tube configuration has a special mode of vibration.
Resonator.
In below Images, it shows.
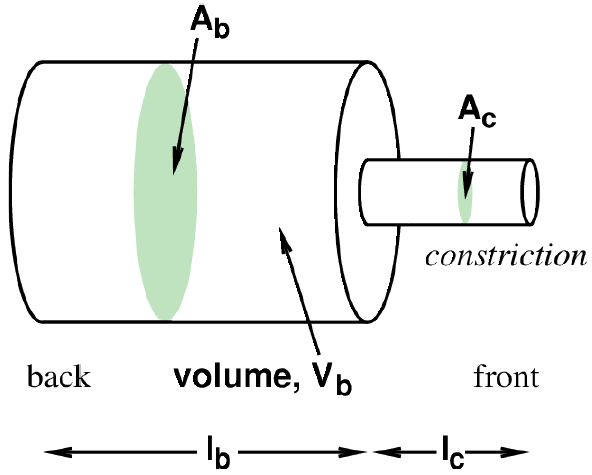
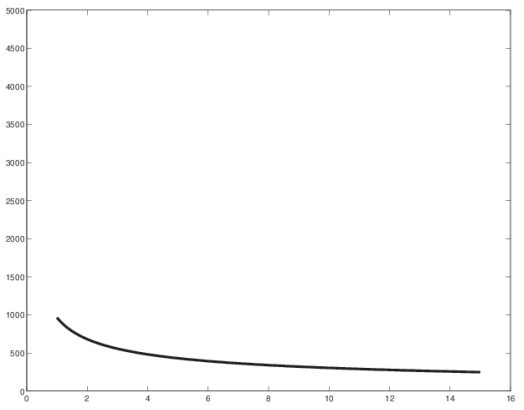
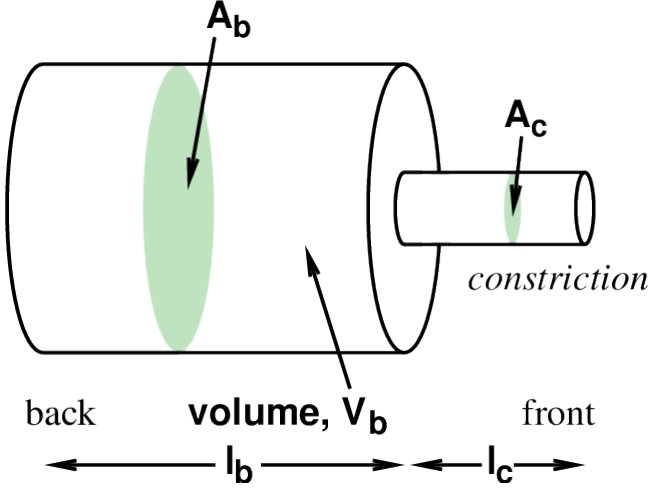
back cavity volume, Vb = Ab lb constriction volume, Vc = Ac lc.
In below Images, it shows.
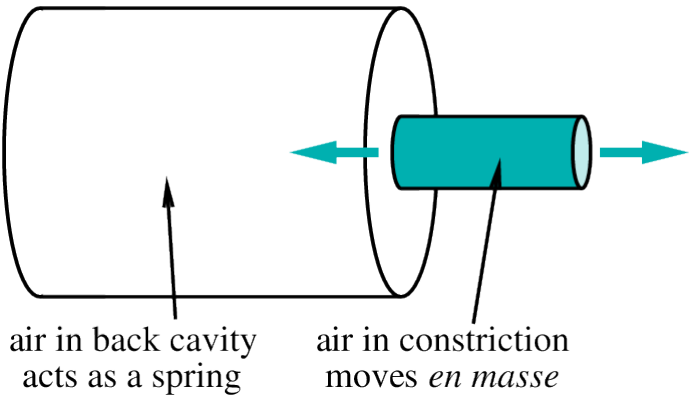
air in constriction moves back and forth like a piston in a cylinder.
The formula.
In below Images, it shows.
Where,
f is the resonant frequency of the system.
Ac is the area of the constriction.
lc is the length of the constriction.
Vc is the volume of the back cavity.
c is the speed of sound in air.
The Resonance.
worked in proper units.
Ac = 15 mm2 = 15 X 106 m2, meter square.
lc = 1 cm = 1 X 102 m.
Vb = 60 cm3 = 60 X 10-6 m3, meter cube.
c = 350 ms-1, meter per second.
In below Images, it shows.
≈ 280 Hz.
Thick line is resonance, for parameters as in examples, (a constriction length of 1 cm).
In below Images, it shows.
What about other formants?.
Resonance is at a low frequency – so it is F1.
– but F2 and F3 in this case?.
A system can have multiple resonances ?.
There must be other resonances of the vocal tract.
Other resonances.
Add a front cavity, to complete the vocal tract model.
In below Images, it shows.
Approximate each tube, as either completely closed, or open at each end.
In below Images, it shows.
A tube that is open at one end, closed at the other.
It is resonances are at frequencies f1, f2,.... where.
fn = (2n - 1) X c / 4L.
Now, for a tube open at both ends.
fn = nc / 2L.
And for a tube closed at both ends.
fn = nc / 2L.
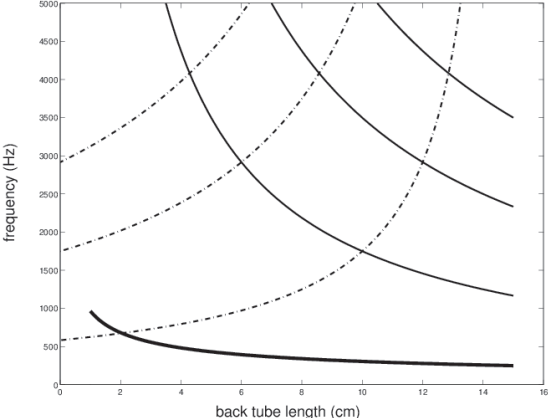
Three tubes: back and front cavities, and constriction.
– constriction is very short ! very high resonant frequencies, so neglect it.
Back and front cavity length varies, as position of constriction moves, depends on tongue position.
Back cavity resonances.
Back cavity length depends, on position of constriction.
In below Images, it shows.
Add in the front cavity resonances.
Dotted lines are front cavity resonances.
In below Images, it shows.
All three resonances together.
Thick line is Resonance.
In below Images, it shows.
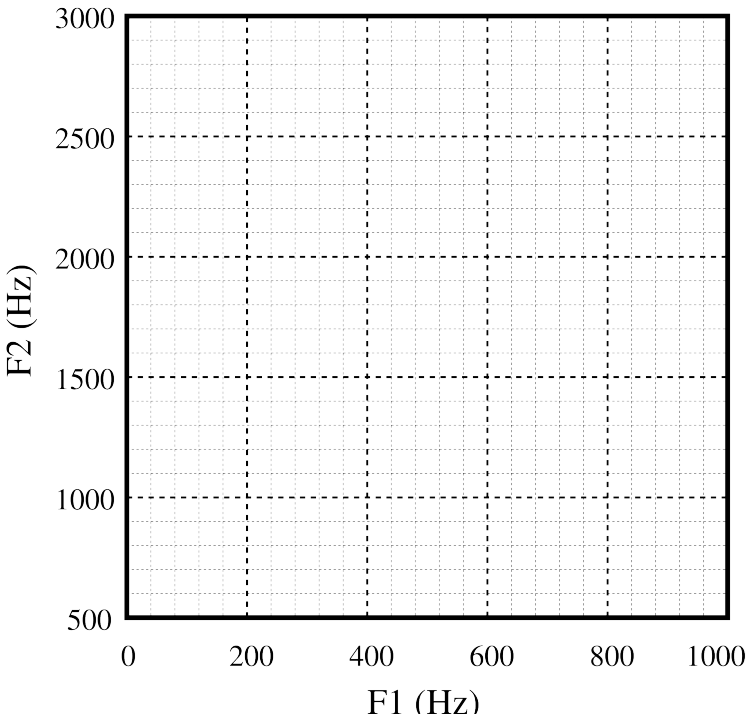
A prediction.
For the high-front vowel [i] – back tube length of around 11 to 12 cm, (Centimeter).
Plot shows.
• F1 ≈ 280 Hz.
• F2 ≈ 1700 Hz.
• F3 ≈ 2200 Hz.
which is in the right ball-park for high vowels, which have low F1 and front vowels which have high F2.
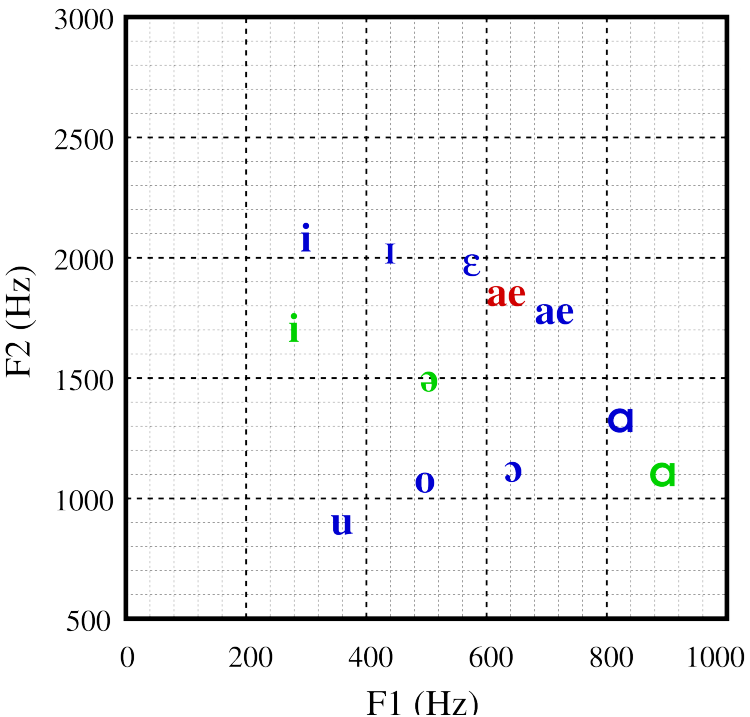
What is this vowel?.
• F1 ≈ 620 Hz.
• F2 ≈ 1850 Hz.
• plot on chart.
In below Images, it shows.
The other predictions.
Neutral vowel: [ə], schwa, vowel, (upside-down e): F1 = 500Hz, F2 = 1500 Hz.
Low, back, unrounded vowel: [a], unrounded vowel: F1 = 900 Hz, F2 = 1100 Hz.
High-front vowel [i]: F1 = 280Hz, F2 = 1700 Hz.
In below Images, it shows.
Vowels in stop contexts.
So far, only considered isolated vowels: formant values constant throughout the vowel.
Now, vowels before and after stops: stop identity will change formant values, because articulators will move position.
Formants depend on articulator positions.
In particular, on the tongue position, since it controls the vocal tract shape & size, But also the lips (rounding), since rounded lips extend the overall vocal tract length.
Vowels after stops.
Articulators must first be positioned to make the stop, different stops have different places of articulation.
In other words, articulators are in different positions (they have different settings), then articulators must move to settings required to make the vowel, this movement cannot be instantaneous, Articulators will be moving whilst speech is being produced, moving articulators ! changing vocal tract shape ! changing formants.
Articulators move with limited velocity.
In below Images, it shows.
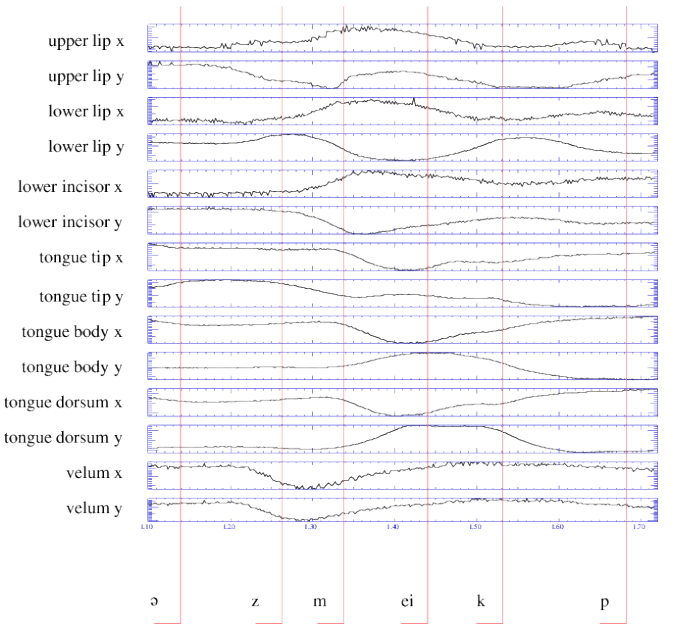
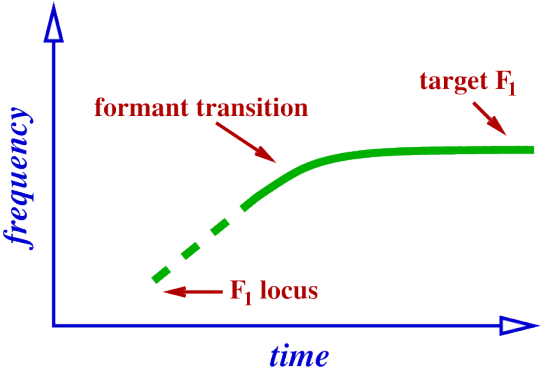
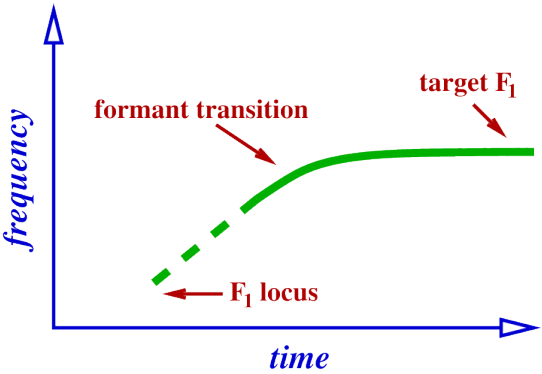
Formant trajectories.
Formants are moving from one value to another, following some path, or trajectory.
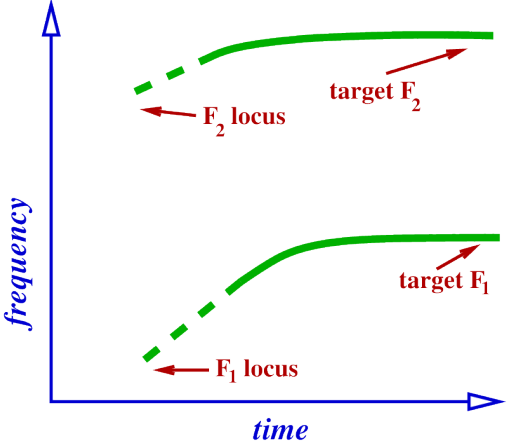
For vowels preceded by stops, trajectories will be heading towards some target frequency and will reach (or get close to) the target at some point within the vowel, but at what frequency do the trajectories start?
Depends on the stop identity [d0...] or [dɔ...], d reversed c, open 0.
Alveolar voiced stop [d].
Followed by back mid-high [o] or back mid-low [ɔ],reversed c, open 0.
– somewhere in the middle of the vowel, formants will approach.
F1 ≈ 500 to 600 Hz.
F2 ≈ 1000 to 1100 Hz.
But, what shape will the formant trajectories be? that is, where will they be coming from Formants of [d].
Not a vowel, does it even have formants?
Formants, simply arise from resonances: if there are resonances, then there must be formants, But during the stop there is (almost) no sound are there still formants?.
Yes, but they may not be audible (or visible on spectrogram).
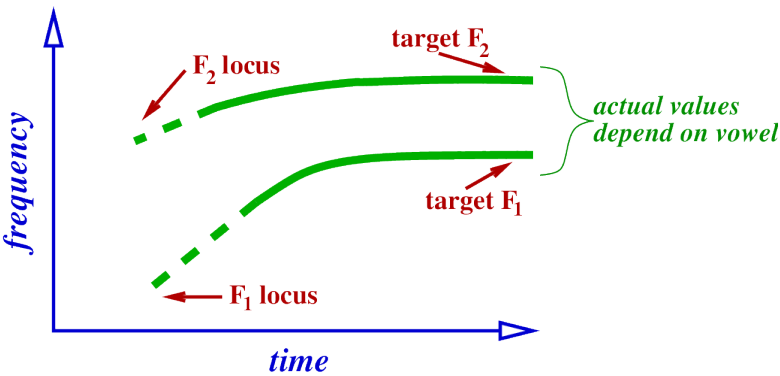
Formant locus.
Formants have values during the stop, may not be able to directly measure this though, because the resonator (cavity) is not being excited.
Where the formant values would be, if we could hear, or see them. Tube model of [dV], where V is a vowel.
What is the articulator setting for [d]?
That is what shape is the tube?
what are the resonances going to be?
Tongue tip touches alveolar ridge, making complete closure, as we release the closure and move into the vowel.
short, narrow opening between tongue tip and alveolar ridge.
sound familiar?
Tube configuration during stop closure..
In below Images, it shows.
Tube configuration during stop release.
In below Images, it shows.
During release of closure.
Narrow constriction opens up, cross-sectional area grows.
What does this mean in terms of resonance?
What mode of resonance will produce F1?
– F1 is whatever the lowest resonance in the system is in this configuration, that will be a resonance.
In below Images, it shows.
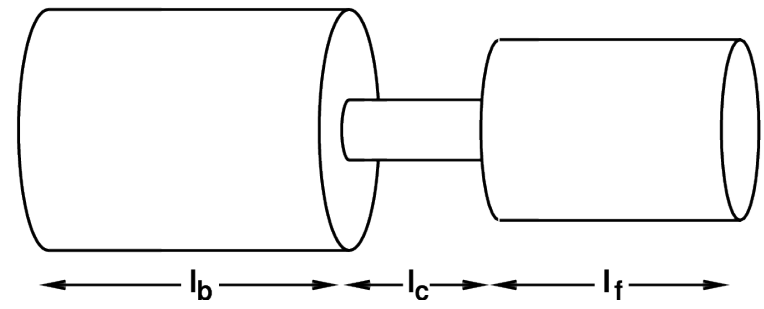
Back cavity volume, Vb = Ab X lb.
Constriction volume, Vcc = Ac X lc.
In below Images, it shows.
Air in constriction moves, back and forth, like a piston in a cylinder.
In below Images, it shows.
Where,
f is the resonant frequency of the system.
Ac is the area of the constriction.
lc is the length of the constriction.
Vb is the volume of the back cavity.
c is the speed of sound in air.
What happens as Ac increases?.
Assume all other dimensions remain constant, only cross-sectional area of constriction, Ac, varies.
In below Images, it shows.
Ac is initially very small, f is very low.
As Ac increases, f increases.
Locus of F1.
Locus of a formant is where it originates, that is, where it starts, this will be at the point of closure in the stop.
cannot actually observe this locus, since closure means (almost) no excitation of the resonances.
But will see the formant transition into the following vowel.
What is the locus of F1 in [d] ?.
Produced by the resonance, since during release, a very narrow constriction is present, will therefore be very low.
Furthermore, F1 will increase during transition, since area of constriction increases, and target value in following vowel is higher than locus.
What about other stops?.
Pattern will be the same:
stop closure formed at some point in vocal tract.
[p] and [b] – lips meet (bilabial)
[t] and [d] – tongue tip touches alveolar ridge
[k] and [g] – closure is made by tongue against velar region
etc.
Closure released.
Short narrow tube, with wider cavity behind (“wine bottle”).
Resonance ---> low F11 locus.
What about other vowels?.
Pattern will be the same:
Resonance is very low, so F11 will always rise going into the vowel.
The target value, that F11 is heading for will depend on vowel identity.
[a], unrounded vowel: F1 high.
[ɔ], reversed c, open 0, and [ε], epsilon: F11 mid.
[u] and [i]: F11 low.
etc.
Trajectory of F1, during stop-vowel transitions.
In below Images, it shows.
closure ----> release ----> vowel.
Locus will always be low frequency.
Actual value of F1 target will depend on vowel identity.
What about F2.
Need to find the locus of F2 during stop closure, this time it would not be a resonance, since there is one Helmholtz resonance in the system.
It is always (very) low frequency, so it produces F1.
Locus of F2 must be one of the other resonances ront cavity back cavity
Locus of F2.
Depends on stop identity.
– stops have differing locations of the closure.
– and therefore differing front/back cavity sizes
Let’s just consider [b], [d] and [g].
[p], [t] and [k] have same places (respectively), they only differing in voicing.
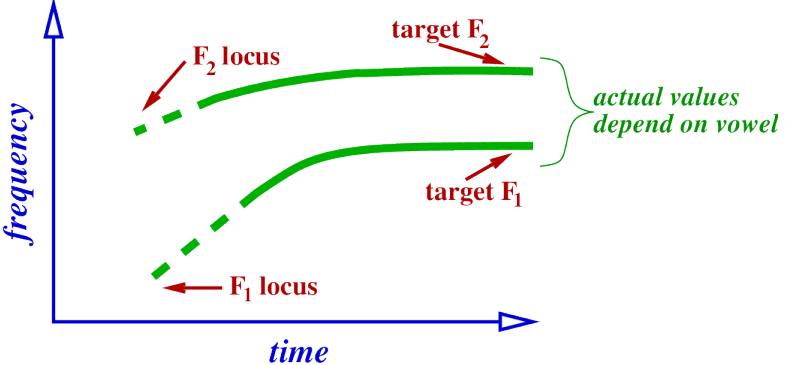
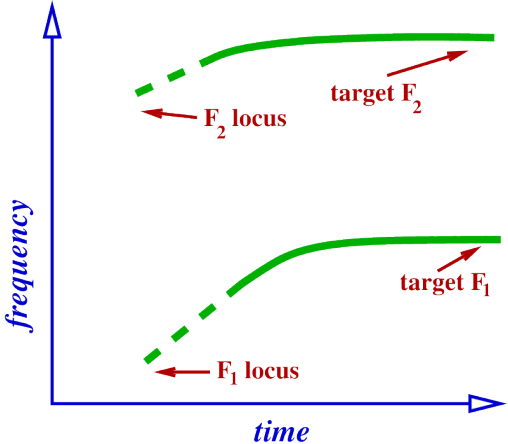
Locus of F2 for [b].
Bilabial – lips form closure, no front cavity and a large (that is long) back cavity.
Back cavity resonance will be F2.
Cavity is as long as it can be (entire vocal tract).
So locus of F2 in [b] will be very low.
– lower than the F2 of any vowel.
– because back cavity is longer than for any vowel.
Therefore trajectory of F2 will always be rising coming out of a [b] into a vowel.
Trajectory of F2 during [bV].
In below Images, it shows.
closure ----> release ----> vowel.
F1 locus as before – very low.
F2 locus also very low.
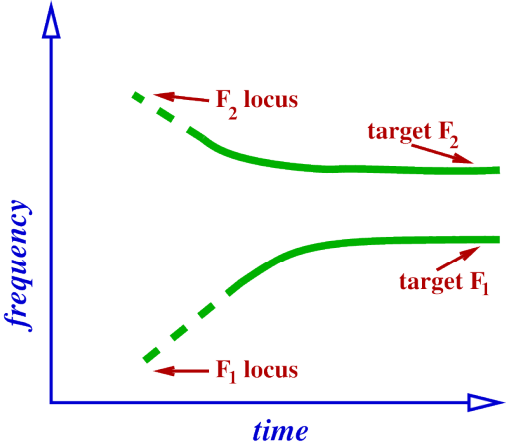
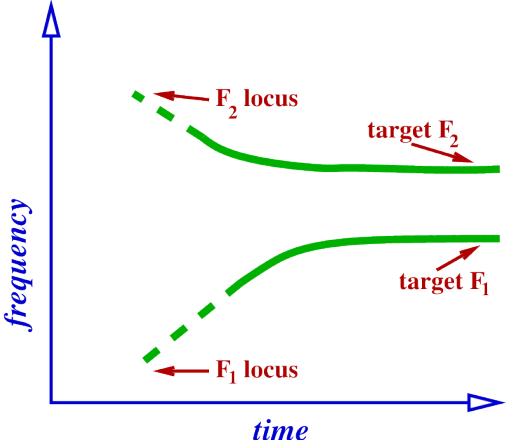
Locus of F2 for [d].
Alveolar (tongue touches alveolar ridge): very short front cavity and a long back cavity, so F2 is produced by back cavity during stop and transition.
Cavity is not as long as in [b], so locus of F2 in [d] will be low, but not as low as for [b], lower than the F2 of some vowels and higher than the F2 of other vowels.
Therefore trajectory of F2 will sometimes be rising coming out of a [d], into a vowel, and sometimes falling, depending on the vowel F2.
Trajectory of F2 during [dV] for V with low F2.
In below Images, it shows.
closure ----> release ----> vowel.
Locus of F2 now around 1800 Hz, target is lower than 1800 Hz.
Trajectory of F2 during [dV] for V with high F2.
In below Images, it shows.
closure ----> release ----> vowel.
Locus of F2 still around 1800 Hz, target is higher than 1800 Hz.
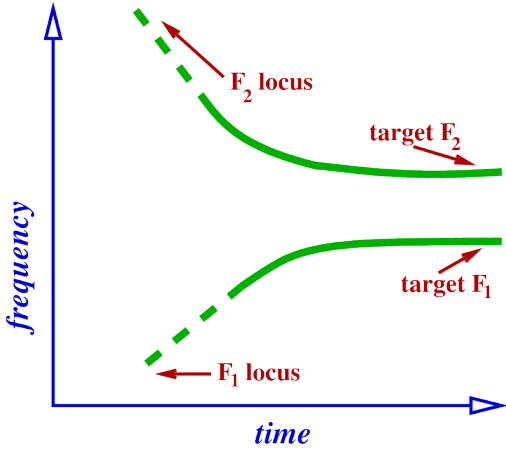
Locus of F2 for [g].
Velar.
– medium length front cavity and a shorter back cavity.
So F2 is now produced by front cavity during stop and transition.
Locus of F2 in [g] will be high.
– higher than the F2 of any vowel.
Therefore trajectory of F2 will always be falling coming out of a [g] into a vowel.
Trajectory of F2 during [gV].
In below Images, it shows.
closure ----> release ----> vowel.
Locus of F2 now always higher than target.
Summary.
both F1 and F2 have a locus and a target for stop-vowel transitions.
Locus.
– is frequency of formant in the stop closure.
– may not be actually present in the speech signal.
– frequency of locus depends on stop identity.
Target.
– is the frequency that the formant approaches in the vowel.
– may not be reached, only approximated.
– frequency of target depends on vowel identity.
Sources of sound.
A proper analysis of the sound produced by.
– the vocal folds.
– including non-periodic sounds.
Which will lead us on to understanding.
– the harmonics in the spectrum of a voiced sound.
– the reasons behind different voice qualities.
And ultimately to.
– a source-filter model of speech production.
Vocal fold action.
In below Images, it shows.
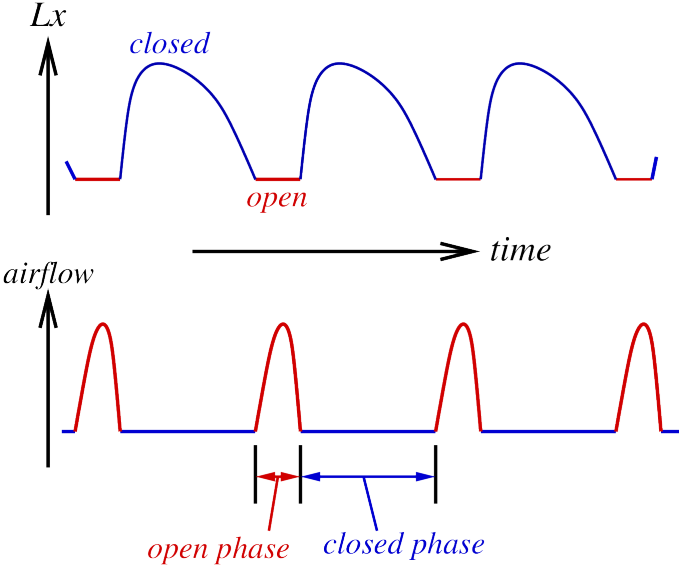
Laryngograph waveform (Lx):.
In below Images, it shows.
Lx vs. glottal airflow.
In below Images, it shows.
The open phase.
Sub-glottal pressure builds up during closed phase.
– vocal folds remain closed.
Sub-glottal pressure eventually forces folds apart.
– airflow starts, and then rises as folds move apart.
– sub-glottal pressure eventually drops.
– then vocal folds start to close due to tension (caused by muscles).
Sub-glottal pressure has dropped.
– airflow reduces.
– glottis (gap between folds) eventually becomes small.
– Bernoulli effect causes pressure in glottis to drop.
– vocal folds drawn into closed position very rapidly (“sucked together”).
As flow velocity increases, pressure decreases, When the glottis becomes narrow, flow velocity through it must increase.
(air is flowing through a smaller area).
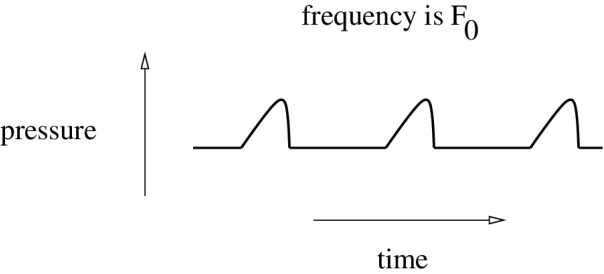
The sound pressure wave just above the folds.
Open phase releases a pulse of higher pressure air into the vocal tract.
– pressure pulse travels upwards through air in vocal tract.
– a moving pressure wave = a sound wave.
So sound pressure waveform just above vocal folds is.
In below Images, it shows.
Analysis of glottal pressure wave.
In below Images, it shows.
Fourier analysis of glottal pressure wave.
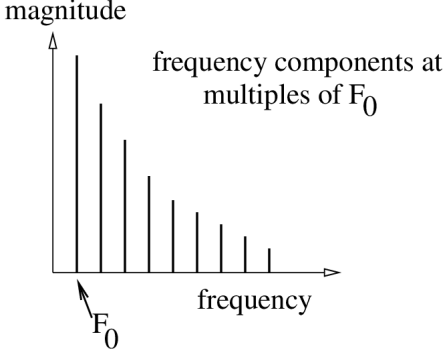
Contains energy at frequency F0.
And at every multiple of F0: 2 X F0, 3 X F0, 4 X F0, ...
These are the harmonics of F0.
Harmonics of F0.
Fundamental frequency is F0.
– also known as the first harmonic.
The component at 2⇥F0 is the second harmonic.
The energy of the harmonics decreases as frequency increases.
The spectrum of the glottal pressure wave.
In below Images, it shows.
Magnitude drops off as frequency increases.
Voice quality.
Vocal tract can be modelled as a tube.
– can only change shape or area.
– which just controls formant frequencies.
What about voice quality differences?
– what exactly do we mean by voice quality?
And what determines voice quality?.
Glottal waveform can vary.
Ratio of.
– open phase to closed phase.
Degree of closure during phonation.
– complete or partial (“leaky”).
Lack of phonation.
– vocal folds do not vibrate at all.
– unvoiced sounds.
– whispering.
The vocal folds.
In below Images, it shows.
Modal voice.
Normal speaking voice.
Enough tension in vocal folds to allow vibration.
– vocal folds vibrate during voiced sounds.
– complete closure is achieved during closed phase.
F0 in central region of speaker’s pitch range.
Breathy voice.
Even during closed phase.
– complete closure is not achieved.
A chink remains open, allowing air to escape throughout the glottal cycle.
– escaping air through narrow opening.
– means turbulent air flow.
– which produces a breathy quality to the voice.
Smoker’s voice.
or....how to give up smoking.
Smoking causes vocal folds and surrounding tissue.
– to become irritated, swollen and dry.
– healthy folds are normally wet (lubricated by mucus).
Which has these effects.
– folds do not close fully during closed phase (breathy quality).
– vibration efficiency reduced (F0 lower).
Result: low pitch and breathy voice quality.
Creak / creaky voice.
Long closed phase.
Relatively short open phase.
– vocal folds tightly closed during closed phase.
Tends to occur at bottom of speaker’s pitch range.
Period of vocal fold vibration tends to become irregular.
Intuitively this is less like a sine wave than modal voice, so we expect it to sound further away from a sine wave sound.
Sine wave = pure tone = “smooth” sound.
Creaky voice = impure tone = harsher or sharper sound.
Whispering.
In below Images, it shows.
No vocal fold vibration.
– folds are closed, apart from a small chink.
– like in breathy voice.
Noise-like sounds wave produced, which is then filtered by the vocal tract in the usual way.
Despite lack of phonation, whispering is intelligible.
Falsetto.
Very high vocal fold tension.
Only internal edges of folds are involved in vibration.
– frequency of vibration is high.
– amplitude of vibration is small.
– speech is relatively quiet.
Trajectory of F1 during stop-vowel transitions.
In below Images, it shows.
Trajectory of F1 during stop-vowel transitions.
closure -----> release -----> vowel.
Locus will always be low frequency.
Actual value of F1 target will depend on vowel identity.
Trajectory of F2 during [bV].
In below Images, it shows.
closure -----> release -----> vowel.
F2 locus very low.
Trajectory of F2 during [dV] for V with low F2.
In below Images, it shows.
closure -----> release -----> vowel.
Locus of F2 now around 1800 Hz, target is lower than 1800 Hz.
Trajectory of F2 during [dV] for V with high F2.
In below Images, it shows.
closure -----> release -----> vowel.
Locus of F2 still around 1800 Hz, target is higher than 1800Hz.
Trajectory of F2 during [gV].
In below Images, it shows.
closure -----> release -----> vowel.
Locus of F2 now always higher than target.
An aside: formant bandwidths.
Formant peaks might be.
– narrow, tall and sharply peaked.
– broad, not so tall and flatter on top.
Each formant therefore has.
– a frequency, measured in Hertz.
– a bandwidth, also measured in Hertz.
What controls bandwidth?
Bandwidth and damping.
A bit harder to get intuitions about than simple resonance.
– when you give one push to a child’s swing.
– it starts to swing (resonate).
– amplitude gradually decays (decreases).
• why does it decay?
Damping – energy is being dissipated (lost) from the system.
(due to air resistance, for example).
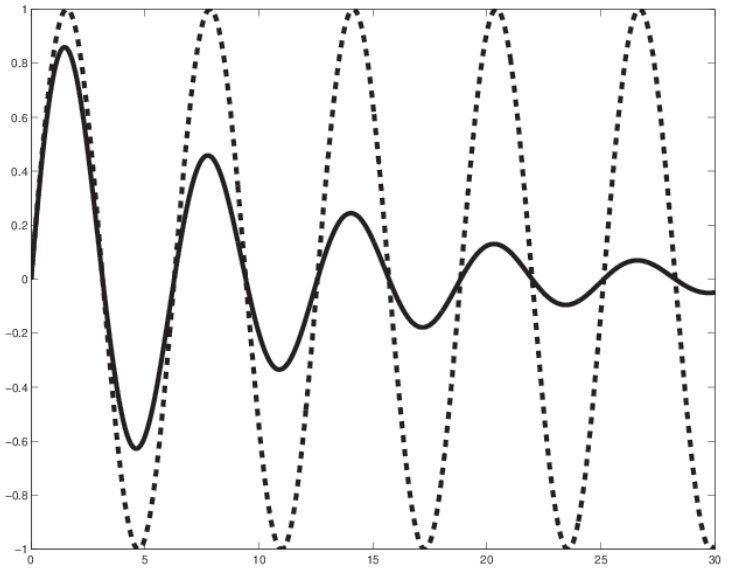
Undamped vs. damped oscillations.
In below Images, it shows.
Undamped vs. damped oscillations.
Undamped oscillations.
– pure sine wave.
– spectrum contains a single line: energy at exactly one frequency.
Damped oscillations.
– decaying sine wave – not pure.
– spectrum contains energy at more than one frequency.
In below Images, it shows.
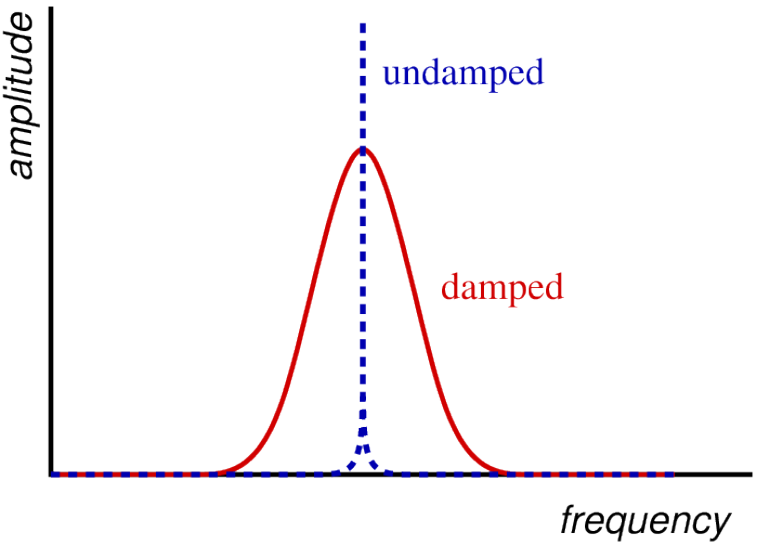
Damping in the vocal tract.
Walls of vocal tract are soft.
– absorb sound energy.
– resonating sound waves are slowly dissipated.
Which is why formant peaks are not tall and narrow.
Fricative sounds.
A very brief look at what makes fricatives.
– sound the way they do.
– sound different from one another (Example: [ s ] vs. [ ∫ ], integral).
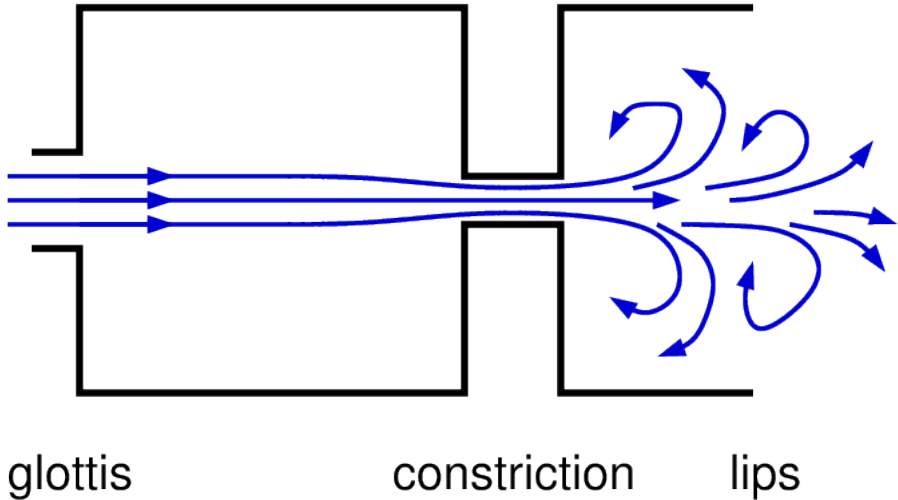
Fricatives: a source-filter approach.
Mentioned the source of sound.
– turbulent airflow.
– caused by, narrow constriction and/or obstacle in airflow.
– turbulent airflow is essentially random, sound wave produced is therefore random, sounds like hissing or white noise.
What shapes the sound?.
The vocal tract.
– source of frication located somewhere in vocal tract.
– sound wave filtered by front cavity.
So, can we explain the spectra of fricatives?
– in terms of location of frication and therefore, size of front cavity.
Turbulence.
In below Images, it shows.
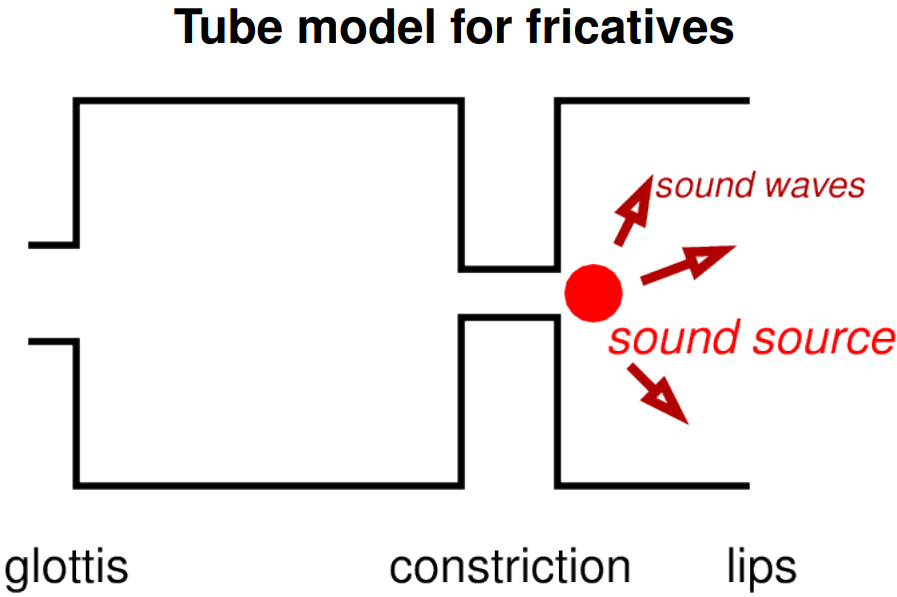
Tube model for fricatives.
In below Images, it shows.
Front cavity resonance.
Size of front cavity.
– determines resonance(s).
Large front cavity means.
– low resonant frequency.
– fricative spectrum has energy peak at lower frequency.
Small front cavity means.
– high resonant frequency.
– fricative spectrum has energy peak at higher frequency.
Tube models for nasals.
Nasal passage becomes connected to vocal tract.
– tube has side branch.
What effect does this have on the spectrum?
Tube model of [m].
Velum lowered.
– nasal passage connected.
Lips closed.
– oral cavity closed at one end.
– connected to pharynx and nasal cavity at other end.
Voiced sound: vocal folds are vibrating.
Tube model of [m].
In below Images, it shows.
Equivalent tube model of [m].
we can treat curved tubes the same as straight ones.
In below Images, it shows.
Two parts to the tube.
In below Images, it shows.
Approximation.
In below Images, it shows.
Resonances.
Main tube.
– resonates in the usual way.
– resonances are formants of nasal.
Side tube.
– resonates too.
– but is a “dead end” – not connected directly to outside world.
– therefore absorbs energy at the resonant frequency/frequencies.
– produces antiformants (known as A1, A2, ...).
Frequency of antiformant(s).
Can easily work out from length of side branch.
– it is the oral cavity.
– lips close one end off.
– so use formula for tube open at one end, closed at other.
For [m], assume length is 8cm (0.08 m, meter) then antiformants are at around.
A1 = 1100 Hz and A2=3300 Hz. Anti-resonance.
This is not simply a lack of resonance.
– it is an actual removal (suppression) of frequencies from the spectrum.
Technical terms:
– pole: another way of describing a resonance.
– zero: another way of describing an anti-resonance.
Vowels only have resonances – that is, just poles.
Nasals have resonances and antiresonances – that is, poles and zeros.
Other nasals - [n].
Oral branch still closed.
– but not by lips, as in [m].
– but further back.
Oral branch no shorter than in [m].
Assume length is 5.5 cm, centimeter, (0.055 m, meter) then antiformants are at around.
A1 = 1600 Hz and A2 = 4800 Hz.
What do zeros look like in the spectrum?.
Poles (resonances) appear as peaks in the spectrum.
Zeros (anti-resonances) appear as dips.
– on a spectrogram: an area with low energy (a “gap”).
The lowest antiformant (A1) is easiest to see.
– for [m] – Area of low energy around 1100 Hz.
– for [n] – Area of low energy around 1600 Hz.
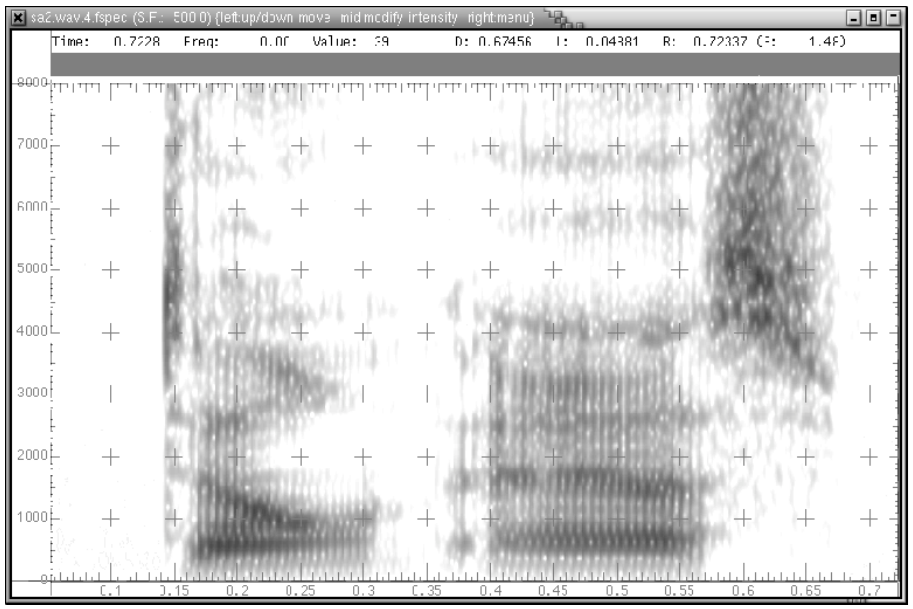
Spectrogram of “...don’t ask...”.
In below Images, it shows.
Spectrogram of “[...as]k me t[o...]”.
In below Images, it shows.
Laterals.
Can use a similar model to nasals [n] and [m].
For [l].
– tongue tip makes contact with palate.
– but vocal tract remains open around edges (that is why it is called a lateral).
– a pocket of air remains above the tongue.
– a simplified tube model for this will have.
* tube for vocal tract.
* side branch for air pocket.
Tube model for [l].
In below Images, it shows.
– An antiformant due to the sidebranch.
Formant bandwidths of nasals.
Bandwidth is due to damping.
– more damping means larger bandwidth.
In vocal tract.
– soft tube walls provide damping.
So, a greater area of tube wall means more damping.
– during nasals, nasal cavity adds extra tube wall area.
– therefore, nasals have greater formant bandwidths.
Lip rounding.
Main effect of rounding is that.
– lips protrude more.
Thus making the vocal tract longer.
– and affecting the formant values: they are lowered.
– particularly those formants associated with the front cavity.
Precisely which formant is most affected depends on the vocal tract configuration.
Often F3 is most strongly lowered.
Quantal theory.
First aspect of quantal theory:.
articulatory “slop” is allowable.
For a range of articulatory configurations.
– acoustic output varies only a very small amount.
And, most importantly, these three behaviours can easily be acheived.
without precise muscle control.
That is, we can get away with a little articulatory “slop”.
Quantal theory: fricatives.
Require a constriction to create turbulent airflow.
– articulators too far apart: laminar flow.
– too close: a stop (closure).
But for a (small) range of constriction sizes.
– turbulence is caused.
– acoustic signal essentially independent of constriction area.
So, although constriction area must be fairly accurately acheived, some articulatory “slop” is allowable.
Second aspect of quantal theory:.
abrubt changes.
Regions of stability.
– Example: vocal folds have three distinct modes of behaviour.
Abrubt transitions between these regions.
– onset of phonation as folds come together is relatively abrubt, not gradual.
– turbulence during fricatives created suddenly as constriction area becomes small enough.
Quantal theory: vowels.
Across the languages of the world.
– some vowels are more common than others.
– why?.
Quantal theory provides one possible explanation.
Resonances: two tube model.
In below Images, it shows.
dotted lines are front cavity resonances.
Quantal theory: preferred vowel [A].
Certain regions of the diagrams (i.e. certain vocal tract shapes).
– produce essentially constant acoustic output (i.e. filter has same frequency response).
– even when small variations are made about that vocal tract shape.
Example: for back cavity length of around 7 to 9 cm, centimeter, F1 and F2 do not vary very much.
Which would predict that [A] is preferred vowel.
Resonances.
In below Images, it shows.
thick line is Resonance.
Quantal theory: preferred vowel [i].
For back cavity length of 9 to 11 cm, centimeter, there is a stable F2 region.
– which predicts that [i] will also be a preferred vowel.
Similar reasoning can be used to predict another preferred vowel: [u].
Does anybody speak a language without these vowels: [A, i, u] ?
Alternative explanation for preferred vowels: adaptive dispersion.
A fancy name for an intuitively very obvious thing.
– preferred vowels are widely spaced in formant space.
– therefore easy to produce so they sound different from one another and also easy to perceive.
So vowels with extreme F1 and F2 are preferred: [A, i, u].
Noting that we need to look at F1 and F2 on a perceptual frequency scale.
This only talks about vowels, whereas quantal theory attempts to make predictions about other (all?) sound classes.
Psychoacoustics.
Two lectures on properties of human auditory system.
1: biological basis.
2: consequences for speech perception.
Human auditory system non-linear in various ways.
Example: frequency scale, amplitude sensitivity.
We will look at.
– why this is.
– what this means for speech.
Psychoacoustics.
Biological basis
Human auditory system.
– anatomy.
– physiology.
– a functional model.
– non-linear properties.
Anatomy of the auditory system:
Peripheral auditory system (that is the part not in the brain).
Outer ear.
– collects sound.
Middle ear.
– system of bones transmits sound to inner ear.
Inner ear.
– converts sound waves into nerve impulses.
Anatomy of the auditory system: outer ear.
Directional sound gathering device.
– having two ears allows us to localise sounds.
– can face sound source to “focus”.
– can distinguish sounds in front / behind us.
Anatomy of the auditory system: middle ear.
Function: to transmit sound from outer ear (air filled) to inner ear (fluid filled).
– sound waves hit tympanic membrane (eardrum), causing it to vibrate.
– system of three bones conducts vibrations from eardrum to inner ear.
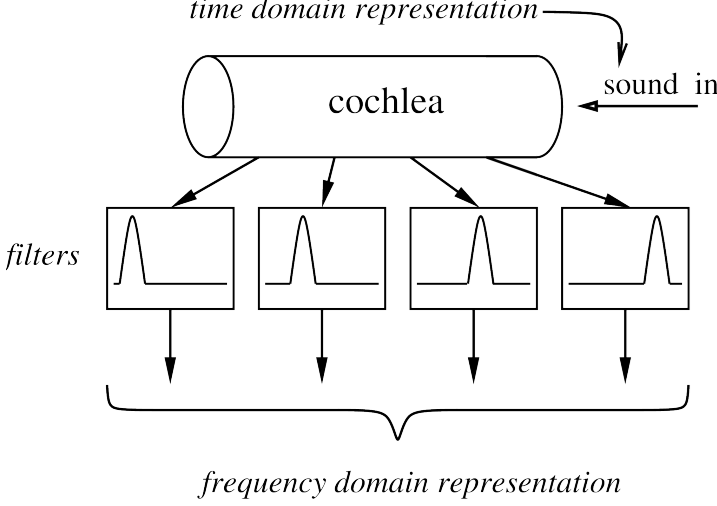
Anatomy of the auditory system: cochlea.
Cochlea: a fluid filled tube.
– converts sound waves to nerve impulses.
– decomposes signal into frequency components.
Anatomy of the auditory system: hair cells in the cochlea.
Convert movement (due to sound waves travelling in the cochlea) to nerve impulses.
– tiny hairs caused to move by sound wave.
– hair movement triggers nerve firing.
– nerve signal sent along auditory nerve to brain.
Physiology of the auditory system: cochlea, that is, what function does it perform, and how?
Takes complex sound wave.
– and decomposes it into frequency components.
Inside cochela, is the basilar membrane.
Thin and narrow at one end, thick and wide at the other.
Physiology of the auditory system: basilar membrane.
Small things resonate at high frequencies.
– thin and narrow end of membrane responds to higher frequencies.
– causing membrane to displace (move) – actual amount of movement is very small.
– movement is sensed by hair cells.
Physiology of the auditory system: hair cells.
Movement of basilar membrane causes.
– shearing (sideways) force on hair cells.
Cochlea functional model, Acts much like a bank of filters (i.e. resonators).
In below Images, it shows.
Frequency sensitivity/discrimination.
Resonances are spaced out along the basilar membrane which runs the length of the cochlea.
– but not linearly (evenly) spaced on a Hertz scale.
What scale are they spaced on?.
What are the consequences for speech perception?
Non-linear frequency scales.
Two aspects to the frequency scale that go hand-in-hand.
– ability to distinguish two similar tones varies with absolute frequency.
– perceived difference of two tones depends on absolute frequency.
as well as relative difference in frequencies.
Both due to the same underlying physiological reason.
– the positions along the basilar membrane that respond to different frequencies are not spaced linearly.
Just-noticable-difference (JND).
Minimum frequency difference required for perceptual difference.
– varies with frequency.
– exact figures depend on experimental method used.
For example, using sequential presentation of pure tones:
Up to around 1000Hz (1kHz): JND is about 2 Hz.
Above 1000 Hz: JND is around 0.2% of the frequency.
6 Hz at 3 kHz, 14 Hz at 7 kHz, ...
Frequency sensitivity/discrimination.
Non-linear frequency scale.
Based on perceptual experiment.
Roughly:
– frequency scale linear up to 1 kHz.
– then logarithmic.
What does a logarithmic scale actually mean?.
Perceived frequency difference depends on ratio of frequencies in Hz.
Example: perceptual distance between 2kHz <--> 4kHz is same as between 4kHz <--> 8kHz and between 8kHz <--> 16kHz.
Perceptual frequency scales.
Often, more useful to use perceptual scale than a linear Hertz scale.
– various scales have been proposed, all very similar.
– three most popular: Mel, Bark and E R B (equivalent rectangular bandwidth).
All have roughly same properties:
– frequency scale linear up to 1kHz
– then approx. logarithmic.
Non-linear amplitude sensitivity.
It can perceive very quiet sounds.
– but also stand very loud sounds (at least briefly) without pain/damage.
Can conduct perceptual experiments.
Example: ask subjects to adjust one sound to be half/same/twice loudness as a reference sound.
For a given frequency, perceptual loudness scale is essentially logarithmic.
Across different frequencies, it is very non-linear.
Bels and decibels (dB).
Define a logarithmic scale for sound pressure level (SLP).
– such that a factor of 10 change in intensity is 1 Bel or 10 dB (decibel).
Intensity is proportional to the square of sound pressure level (SPL).
– a factor of 10 change in SPL is 20 dB (decibel).
The dB SLP scale measures physical sound pressure.
Human perception caries with frequency, so there is a perceptual version of the scale: dB SL (sensation level).
Non-linear amplitude sensitivity.
Across different frequencies.
– signal amplitude must vary to keep constant perceptual loudness.
Most sensitive across frequencies found in speech.
Auditory system is particularly sensitive across the frequency range: 500 to 5000 Hz.
Which co-incides, with the frequencies, containing the information in speech signals.
• using non-linear frequency scales to analyse speech.
– reveals F1 and F2 more easily than linear scale.
• other aspects of human audition affecting speech perception.
– limited frequency resolution.
– masking in time and frequency.
Perception of speech (and other sounds).
Non-linear frequency scales.
– and critical bands.
Higher level (more central) processing.
– masking.
some sounds can obscure others.
– binaural hearing.
cocktail party effect.
Perceptual correlates of acoustic properties.
Acoustic Property.
Perceptual Phenomenon.
Intensity.
Loudness.
Frequency.
Pitch.
Duration.
Perceived Duration.
Spectral Properties.
Timbre.
These can interact.
Example: for short sounds, longer duration gives perceptually greater loudness.
loudness.
Loudness is the perceptual correlate of intensity.
Loudness of sounds.
– roughly corresponds to logarithm (log) of intensity.
Intensity is a physical property of the sound wave.
– intensity is the mean squared amplitude of the sound pressure.
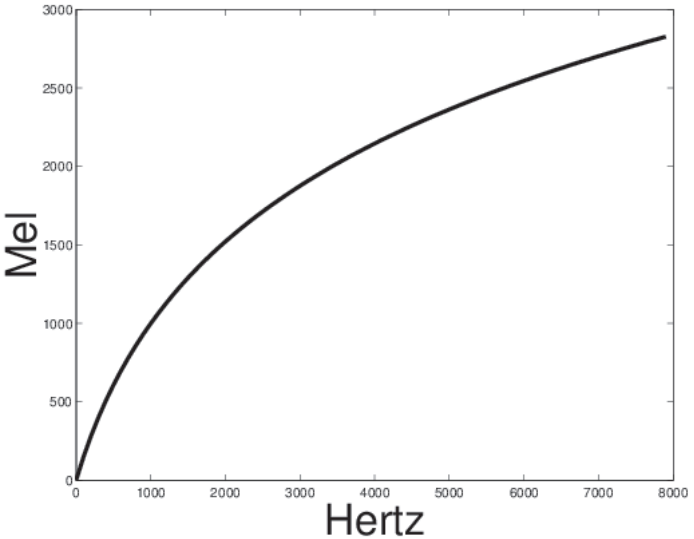
Non-linear frequency scales.
Example: the Mel scale.
In below Images, it shows.
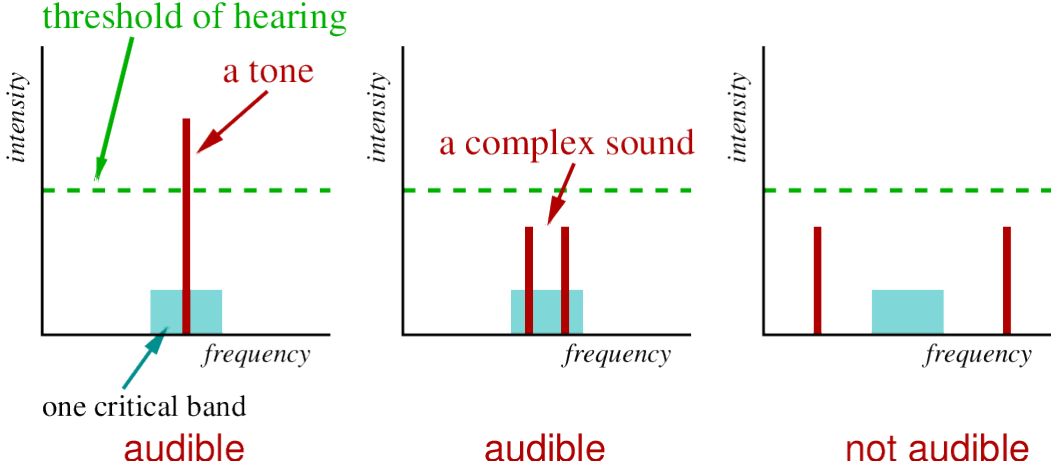
Critical bands.
Frequency resolution of cochlea is limited.
– two sounds of slightly different frequency may have same perceived pitch.
Width (in Hz) of critical bands increases with frequency (in Hz).
Auditory spectrograms.
Vertical axis uses a perceptually-motivated frequency scale.
– lower frequencies more spread out – see more detail.
– for speech: formants more separated and easy to distinguish.
Sometimes also model other aspects of the cochlea, Example: critical bands.
– then called cochleagrams.
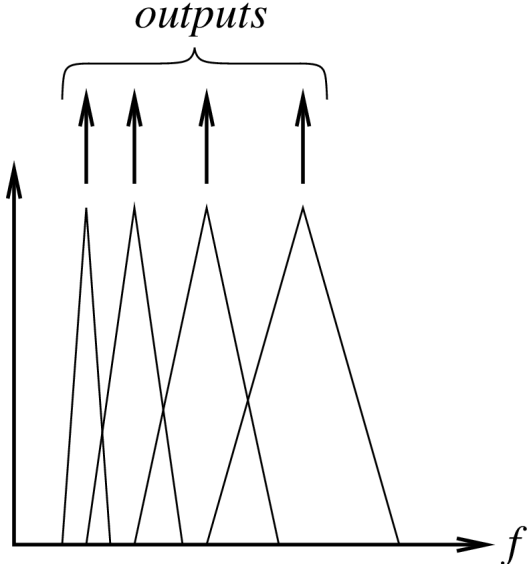
Cochlea: functions as set of overlapping filters.
Filters spaced non-linearly along the frequency scale.
Each filter corresponds to one critical band.
Accounts for:
– limited frequency resolution.
– non-linear relationship between frequency and perceived pitch.
– some aspects of masking.
Cochlea as a filterbank.
In below Images, it shows.
Loudness of complex tones.
Loudness is approx. log (intensity).
how loud is a sound consisting of two tones?
If within a single critical band.
– intensity is summed.
– then “converted” to loudness.
Otherwise.
– loudnesses are summed.
Implications for perception of complex sounds.
If two tones fall within a single critical band, intensity of each tone required for detection of this complex tone is half that for a single tone.
In below Images, it shows.
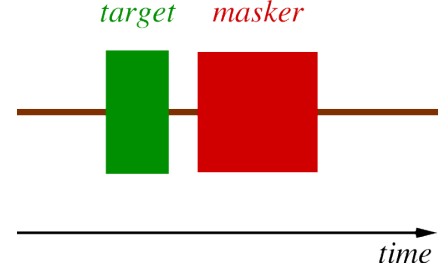
Masking.
Masking means reducing our ability to detect some acoustic event.
One tone can inhibit perception of another tone.
– when tones are presented together.
– or even when presented separately.
Can measure this using perceptual experiments.
Masking in the basilar membrane.
Presenting two tones of different frequency simultaneously.
– louder tone can mask quieter one.
Can explain in terms of critical bands.
this process may take place in the basilar membrane.
However, masking can occur in ways that cannot be explained in terms of the peripheral auditory system, Masking in more central processes.
Masking effect can happen even if.
– two tones not presented simultaneously.
– Example: in sequence or binaural presentation.
Masking.
In below Images, it shows.
Masking tone or narrow-band noise.
Target tone.
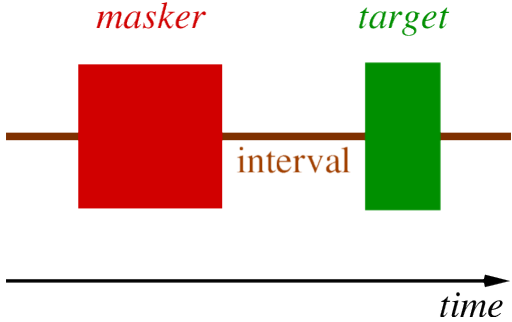
Forward masking.
In below Images, it shows.
First present masking tone.
Then target tone.
– if interval is less than around 300ms, masking occurs.
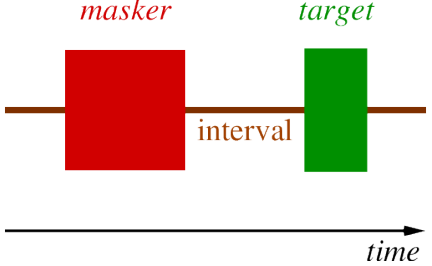
Backward masking.
In below Images, it shows.
First present target tone.
Then masking tone.
– can still get masking, if masking tone is presented less than 40 ms after target tone.
Central masking.
Present target tone to one ear.
And masking tone to other ear.
– masking effect observed.
Therefore masking does not (only) happen in the peripheral auditory system, there must be some central interaction.
Masking and complex sounds.
Complex sounds (Example: speech).
– essentially composed of a number of pure tones.
– so masking can occur between these tones.
Implies that.
– we cannot perceive all the component sounds of speech.
– or indeed of other sounds.
This knowledge is very useful for audio coding/compression.
Example: mp3.
Speech (and other audio) coding.
Often, want to compress audio signals.
– for storage (Example: minidisc, mp3 coding).
– or transmission (Example: mobile phones, digital radio, satellite links,
transatlantic phone lines, internet, etc.)
For maximum compression.
– need to discard some of the signal.
– that is lossy compression.
knowledge of properties of human auditory perception.
– helps us choose what to discard.
mp3 audio compression.
Normally, 1 minute of CD-quality sound takes about 10Mb (70 minutes of music on one CD = around 700 Mb).
– with mp3 compression, we can reduce the space required by a factor of over 10.
– so one CD can hold over 10 hours of near-CD-quality music.
to acheive this compression, some information must be discarded.
Psychoacoustic models are used to determine what parts of the signal can be removed with little or no perceptual difference.
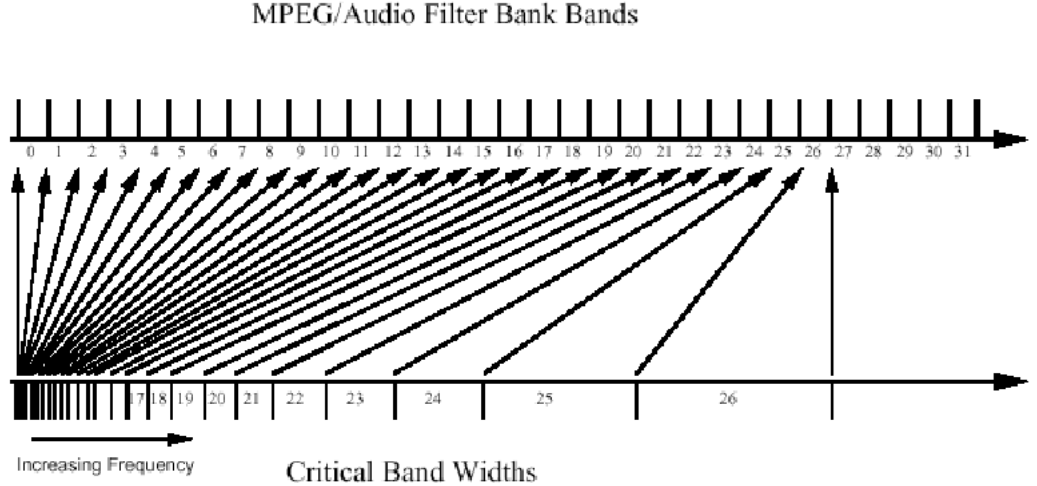
mp3 auditory filterbank.
Transforms signal to frequency-domain representation (like a Fourier transform, except on a non-linear frequency scale).
In below Images, it shows.
mp3 masking model.
In below Images, it shows.
Cocktail party effect.
Binaural hearing.
– allows us to localise sound (determine direction).
– makes it easier to pick out one particular sound in a noisy environment.
We already saw how masking can inhibit detection of a sound.
– binaural hearing helps separate masker and sound of interest.
Binaural unmasking.
Present a masker and a target tone.
If both presented to just one or to both ears.
– the target tone is not detected.
Now present.
Masker + target to left ear.
Just the masker to the right ear.
– this makes it possible to detect the tone.
Binaural unmasking.
the target is perceived as being close to the left ear.
the masker is perceived as being directly in front.
the separation of mask and tone in space results in unmasking.
– the target tone is now detected.
Only some central processing can be doing this – the signals from both ears are required.
Summary
Some peripheral processing in the middle ear and cochlea.
– gain control and amplitude compression (logarithmic).
– non-linear frequency scale (compresses higher frequencies).
– critical bands.
And other, more central processes.
– masking and un-masking / cocktail party effect.
One application of this knowledge.
– audio compression.
The Human Voice, in the Universe, or in the Space, or in the outside planet Earth.
No, a human voice does not move, in the Universe, or in the Space, or in the outside planet Earth.
The Sound does not travel, in the Universe, or in the Space, or in the outside planet Earth.
The Sound waves travel, through vibrations in a medium, like air, or water, or solid, and cannot travel through empty space.
In the Universe, or in the Space, or in the outside planet Earth, there are no atoms or molecules to carry sound waves, so there is no sound.
The Sound waves lose, energy over time.
As they travel through a medium, causing them to get quieter, and quieter until they disappear.
The Sound waves are reflected, by mediums.
Like walls, pillars, and rocks, which is known as an echo.
Can you hear sound in space.
No, you cannot hear any sounds, in near-empty regions of the space.
The Sound travels, through the vibration of atoms, and molecules in a medium, (such as Air, or Water, or Solid).
In the Universe, or in the Space, or in the outside planet Earth, where there is no Air, Sound has no way, to travel.
Is it possible, to send messages, through brain waves of the human?.
Technical telepathy is the best method.
The electrical nature of the brain allows, not only for sending of signals, but also for the receiving of electrical pulses.
Technical telepathy is the use of technology to communicate thoughts without Sound.
It involves, using brain-computer interfaces (B C I s), to translate brain activity, into signals, that can be transmitted, to another person.
Electroencephalography (E E G): A cap of electrodes is placed, on the head to read brainwaves.
Transcranial magnetic stimulation (TMS): An electromagnet is placed over the head, to stimulate brain activity.
These can be delivered, in a non-invasive way, using a technique called transcranial magnetic stimulation (TMS).
Neural decoding: Technologies that translate thoughts, into written or spoken language.
Potential applications.
Communication: Allowing people, to communicate their thoughts, and feelings, without speech, or signs.
Mobility: Restoring mobility, for paralyzed people, by stimulating muscles directly.
Brain-machine communication: Revolutionizing, how people interact, with machines.
What is the highest brain wave in Humans?.
Gamma brain waves are the fastest brain waves, produced inside human brain.
Although, they can be hard to measure accurately, they tend to measure above 35 Hz, and can oscillate as fast as 100 Hz.
Human brain tends, to produce gamma waves.
How to measure brain activity in humans.
The Human Brain, is difficult to study, not only, because of its inherent complexity.
The billions of neurons, the hundreds or thousands of types of neurons, the trillions of connections.
The Human Brain, also works at a number of different scales, both in the physical sense and in the time domain.
To understand, the human brain’s electrical activity at these scales, no single technology is enough.
As a result, neuroscientists have a suite of tools, at their disposal.
Some of these, such as fMRI and E E G, can be used in humans, because they are non-invasive; they work through, by looking into the skull, But, these tools suffer, from a lack of detail.
To get a more microscopic picture, of neuron activity, researchers turn to human models.
This allows the behaviour of individual neurons, or small groups of neurons, to be analysed in much greater detail.
The main Questions, for which this mission exists.
1. The Human Mouth, and The Human Ears are having, fixed distances, and standard range.
2. The Sound speed is, only 343 meter per second.
3. The Diameter of the Planet Earth, is 12756 killometer, that is 1 crore, 27 lakh, 56 thousand, Meter.
4. How, these Voices or Sounds or Noises are listening, at the same time, that is simultaneously, in every corner of whole World.
5. How, these Voices or Sounds or Noises are listening, by each & every People, inside all the countries of whole World.
6. How, these Voices or Sounds or Noises are listening, by Peoples, in the Universe, or in the Space, or in the outside planet Earth, where no Air or no Water.
7. Why, these Voices or Sounds or Noises are unknown, generating source.
8. Nobody knows, from where generating, these Voices or Sounds or Noises.
9. The Human Eyes are not generating direct sound of visual inputs, and internal verbalization occurs.
10. First Conclusion is, there is no role of, the Human Mouth, and the Human Ears, and the Human Eyes.
11. Only one body part, Human Brain is not having, fixed distances, or standard range.
12. The Human Brain is, no clear boundary, for what, it is capable of.
13. The Human Brain will hold, more than 1 quadrillion pieces of information, That is, 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 pieces of information. Till now, no body has confirmed about human brain's storage capacity.
14. Second Conclusion is, there is definitely role of the Human Brain.
15. There are two ways, to reach our conclusion, One is "Artificial Mode", Second is "Natural Mode".
16. "Artificial Mode" is the way of Electronics chips, transmitters and receivers inside the human brain. Surgically implanted in the skull, and contain electrodes, that creates all Voices or Sounds or Noies from the Human Brain. Another method is, that without knowledge, inserting of electromagnetic chip, inside human body through vein. Through remote control, moving of sensors inside human body parts, and human brain. Artificially controlling of Brain Motor Cortex, through Remote Control, from different places. Another big question arising here. Human technologies inside Earth Planet has till now, particular limitations on modern sciences. So, It may be any technologies, from outside Earth Planet. It can be possible of outer signals, or outer frequencies, or outer vibrations.
17. Third Conclusion is, there is definitely role of Artificial mode of the Human Brain.
18. "Natural Mode" is from the birth of the humans. The Human Brain is the creation of God, inside human body. Till now, nobody has able to create artificial human brain, or no body has able to control natural human brain entirely. Signals inside the human brain are electrical, and chemical signals, that carry information between neurons. The human brain process information, from the senses, and the body, and then translate that information into meaning. Brain waves are electrical signals, include gamma, beta, alpha, theta, and delta waves. Action potentials are electrical signals, that neurons fire across neural networks. Neurotransmitters are chemical signals, that neurons release across synapses, to communicate with each other. Signals travel through Sensory neurons. which are carrying information, from the senses to the brain. Motor neurons are carrying information, from the brain to the muscles, organs, and glands. Interneurons are connecting sensory, and motor neurons. Many signals are processed are Sensory signals, Body Signals. Sensory Signals are come from the senses of Vision, Smell, Listening, Touch, and Taste, which are related to Eyes, Noses, Ears, Fingers, and Tongues. Another sense is called Sixth sense. Is it real. It is only a belief. Yes, the sense of body awareness, called proprioception, is sometimes referred to as the "sixth sense". An ability to know something without using the ordinary five senses. Body signals are coming from inside the body, such as pain, temperature, walking, and heart rate. So, without any machine, the human brain can be work, like a transmitter, receiver, and producing of radio signals. Technical telepathy is the use of technology, to read and transmit thoughts, from one human, to another human. It can be possible. Where science is failing, then its natural mode.
19. Fourth Conclusion is, there is definitely role of Natural mode of the Human Brain. It can be test, by researchers, stopping all artificial methods. If the Transmissions, and the Receivers are continuing after that, then its no way to refuse, the truth of Natural method.
20. Final Conclusion is not yet finalized, for declaration. It is still under Research. Science has no answer, and Researchers are not able, to give final conclusion. Can Humans are able to stop, these invisible Voices, or Sounds, or Noises. This organization giving, an opportunities to all scientists, researchers, and everybody of all countries, to research. That is why, I am donating of "my living Body" & "my living Brain", for scientific research. "To find solutions". "To Stop Invisible Voices listening by each & every people". "To save all peoples of all the countries". "To save our beautiful earth planet". If it is outer signals, from outside Earth Planet, Then how to save, Earth Planet. If It is Natural methods, Then Why? & How? it is happening.
21. This Organization has formed, due to all above Questions, to find answers, and to find solutions.



 Click below to Listen ...
Click below to Listen ...